










اگر تا به حال جمله معروف “چیزها، نه رشتهها”، “Things, not strings” را نشنیدهاید، این جمله از یک پست وبلاگ مشهور گوگل آمده است که راهاندازی گراف دانش گوگل را اعلام کرد. این جمله بیان میکند که گوگل دیگر صرفاً به دنبال نتایج ساده براساس کلمات کلیدی نیست، بلکه میخواهد موجودیت ها و ارتباطات میان موجودیتها مختلف را درک کند تا نتایج بهتری ارائه دهد.
توضیح مترجم: در سراسر این متن کلمه Entity به «موجودیت» ترجمه شده است. هرچند معادل دقیق و رایجی برای این کلمه در فارسی نداریم اما رایجترین عبارت که در سئو نیز استفاده میشود، سئو موجودیت یا همان Entity SEO است. اما به جهت روانخوانی شما هر کجای متن که ممکن است با به کار بردن معادل «موجودیت» ابهام ایجاد شود، در کنار آن Entity اضافه خواهد شد. برای کاربرانی که ممکن است به فارسی «انتیتی» را جستجو کنند نیز چند مورد به این شکل در متن مشاهده میکند.
با وجود گذشت ۱۱ سال از انتشار این جمله معروف، هنوز بسیاری از افراد معنا و اهمیت واقعی این جمله را برای SEO درک نمیکنند. این جمله تلاشی بود تا نشان دهد گوگل دیگر یک الگوریتم ساده تشخیص کلمات کلیدی نیست و چیزهای پیچیدهتری را درک میکند.
سئوی موجودیت در ماه می سال ۲۰۱۲ با معرفی قابلیتهای یادگیری ماشینی گوگل متولد شد. گوگل با استفاده از پایگاههای اطلاعاتی نیمه ساختاریافته و ساختاریافته، توانست معنای کلمات کلیدی را درک کند. به این ترتیب، ابهام ماهیت زبان (nature of language) در نهایت یک راه حل بلندمدت پیدا کرد. اما با وجود اهمیت موجودیتها برای گوگل، چرا طی بیش از ۱۰ سال گذشته، کارشناسان و متخصصان سئو همچنان در مورد موجودیتها سردرگم هستند؟
چهار دلیل اصلی در رابطه با این موضوع مطرح میشود:
- اصطلاح سئوی موجودیت به اندازه کافی به طور گسترده مورد استفاده قرار نگرفته است تا ارائه دهندگان خدمات سئو با تعریف آن آشنا شوند و در نتیجه آن را در واژگان خود بگنجانند.
- بهینهسازی موجودیتها تا حد زیادی با روشهای قدیمی متمرکز بر کلمات کلیدی همپوشانی دارد. در نتیجه، موجودیتها اغلب با کلمات کلیدی اشتباه گرفته میشوند. علاوه بر این، مشخص نبود که موجودیتها چه نقشی در سئو دارند، و واژه “موجودیتها” گاهی اوقات به جای “موضوعات” (topics) توسط گوگل به کار میرود.
- درک موجودیتها و کسب دانش و یادگیری عمیق در مورد آنها نیازمند مطالعه منابع پیچیدهای مثل اختراعات گوگل (Google patents) و آشنایی با موجودیتهایی مانند یادگیری ماشینی است که کاری خستهکننده و ناخوشایند برای بسیاری از افراد محسوب میشود. سئوی موجودیت رویکردی بسیار علمیتر نسبت به سئوی معمولی است و علم برای همهکس جذاب نیست!
- یوتیوب تاثیر بسزایی در گسترش علم و دانش داشته است، اما در عین حال تجربه یادگیری بسیاری از موضوعات را سادهتر کرده است. آن دسته از خالقان محتوا که در این پلتفرم محبوبیت بیشتری داشتهاند، معمولاً هنگام آموزش به مخاطبان خود، راه آسانتری را انتخاب کردهاند. در نتیجه، تولیدکنندگان محتوا تا همین چند سال اخیر وقت چندانی را صرف آموزش موضوع موجودیتها نکرده بودند. به همین دلیل، برای یادگیری موجودیتها لازم است از منابعی مثل محققان حوزه پردازش زبان طبیعی (NLP researchers ) کمک بگیرید و سپس این دانش را در حوزه سئو به کار ببندید. مقالات پژوهشی و اختراعات نیز در این زمینه نقشی اساسی دارند. این موضوع بار دیگر نکته اول یعنی کمبود آشنایی سئوکاران با مفهوم موجودیتها را تایید میکند.
توضیح مترجم: در اینجا به کلمه NLP اشاره شد. این کلمه مخفف Natural language processing است. لازم به توضیح است پردازش زبان طبیعی (NLP) شاخهای از هوش مصنوعی (AI) است که رایانهها را قادر میسازد تا زبان انسان را درک، تولید و دستکاری کنند. پردازش زبان طبیعی این قابلیت را دارد که داده ها را با متن یا صدا به زبان طبیعی بازگویی و بازنویسی کند.
این مقاله راه حلی برای چهار مشکل اصلی در یادگیری و اجرای سئوی موجودیت ارائه میدهد و میتواند به سئوکاران کمک کند تا به طور کامل بر رویکرد مبتنی بر موجودیت مسلط شوند.
با مطالعه این مقاله مطالب زیر را خواهید آموخت:
- موجودیت Entity چیست و چرا مهم است؟
- تاریخچه جستجوی معنایی (semantic search) چیست؟
- چگونه موجودیتها را در صفحات نتایج جستجو شناسایی و استفاده کنیم؟
- چگونه از موجودیتها برای رتبهبندی محتوای وب استفاده کنیم؟
توضیح مترجم: دقت کنید که Semantic SEO با معادل «سئو معنایی» نباید با Entity SEO با معادل «سئو موجودیت» اشتباه گرفته شوند. توضیح بیشتر آنکه Semantic SEO به دنبال یافتن معنا و قصد کاربر از سرچ یک عبارت کلیدی است و روابط بین موجودیتها را تشخیص میدهد و عبارات مرتبط که با هدف کاربر تطبیق دارند را با یکدیگر ترکیب و معادلسازی میکند. در ادامه نیز تعریف دقیقیتری از سئو موجودیت پیدا خواهید کرد.
چرا موجودیت یا انتیتی در سئو سایت مهم است؟
سئوی موجودیت، آینده موتورهای جستجو در انتخاب محتوا و رتبهبندی و تعیین معنای آن است. وقتی این موضوع را با اعتماد مبتنی بر دانش ترکیب کنیم، سئوی موجودیت ظرف سالهای آتی (حدودا ۲ سال) ، آینده سئو را تشکیل خواهد داد. به عبارت دیگر، موجودیتها بسیار مهم هستند زیرا جستجوگرها به سمت درک بهتر محتوا با تکیه بر آنها حرکت میکنند و آینده سئو مبتنی بر موجودیتها خواهد بود.
نمونههایی از انتیتی ها
با این تفاسیر، چگونه میتوان یک موجودیت را شناسایی کرد؟ صفحات نتایج جستجو نمونههای متعددی از موجودیتها دارند که احتمالاً تا به حال آنها را دیدهاید. رایجترین انواع موجودیتها شامل نام شهرها، کشورها، افراد مشهور، برندها و شرکتهاست که میتوان آنها را در صفحات نتایج جستجو مشاهده کرد.
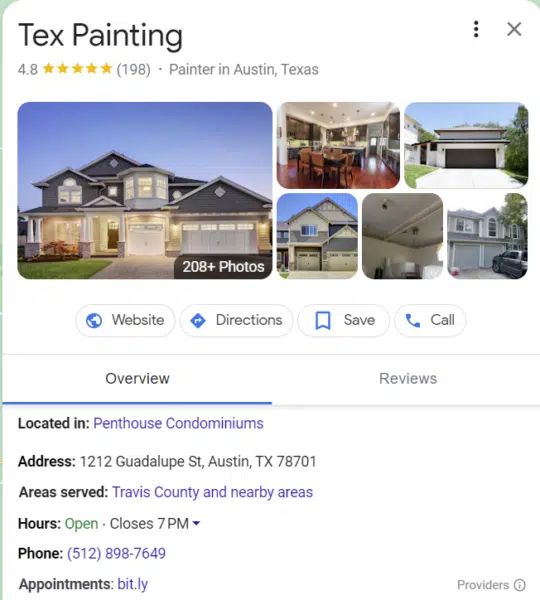
یک پروفایل کسبوکار در نتایج جستجوی گوگل
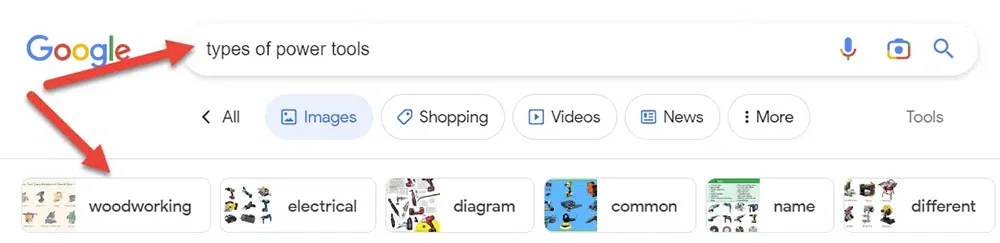
جستجوی تصویر در گوگل
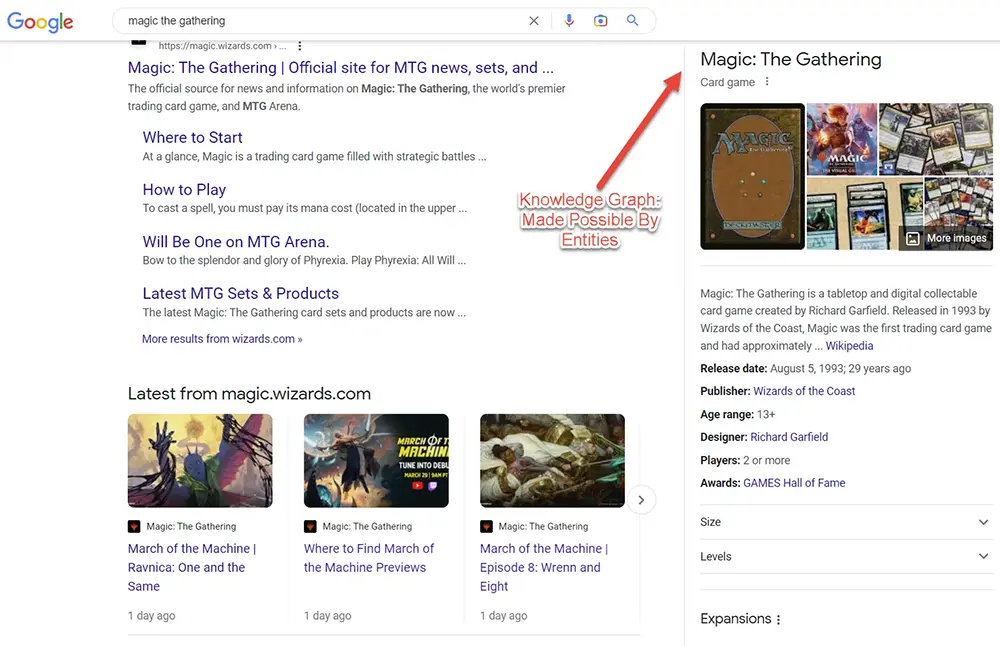
پنل دانش گوگل یا knowledge panel
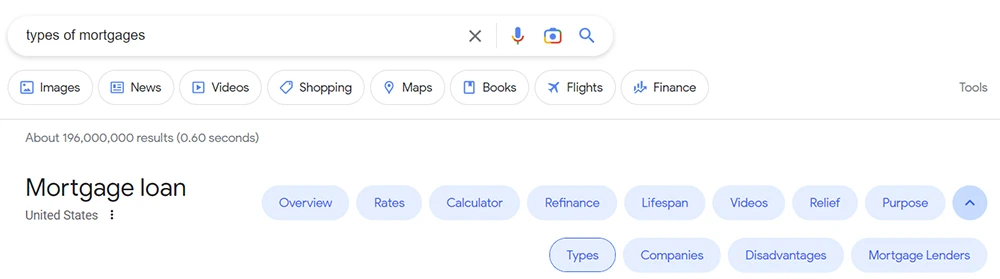
خوشههای نتایج جستجو بر اساس قصد و هدف کاربر از جستجو (Intent clusters)
شاید بهترین نمونه موجودیتها در صفحات نتایج جستجو، خوشهبندی براساس قصد و نیت کاربر از جستجو باشد. هرچقدر یک موضوع بیشتر درک شود، این ویژگیهای جستجو بیشتر ظاهر میشوند. جالب است بدانید یک کمپین سئو میتواند با تمرکز بر موجودیتها، چهره صفحات نتایج جستجو را تغییر دهد. مطالب ویکیپدیا نمونه دیگری از موجودیتها هستند که نمونه عالی از اطلاعات مرتبط با موجودیتها را فراهم میکند.
همانطور که در تصویر مشاهده میکنید، در بالا سمت چپ، این موجودیت دارای انواع ویژگیهای مرتبط با “ماهی” است که از آناتومی آن گرفته تا اهمیت و ارزش غذایی آن برای انسانها را شامل میشود.
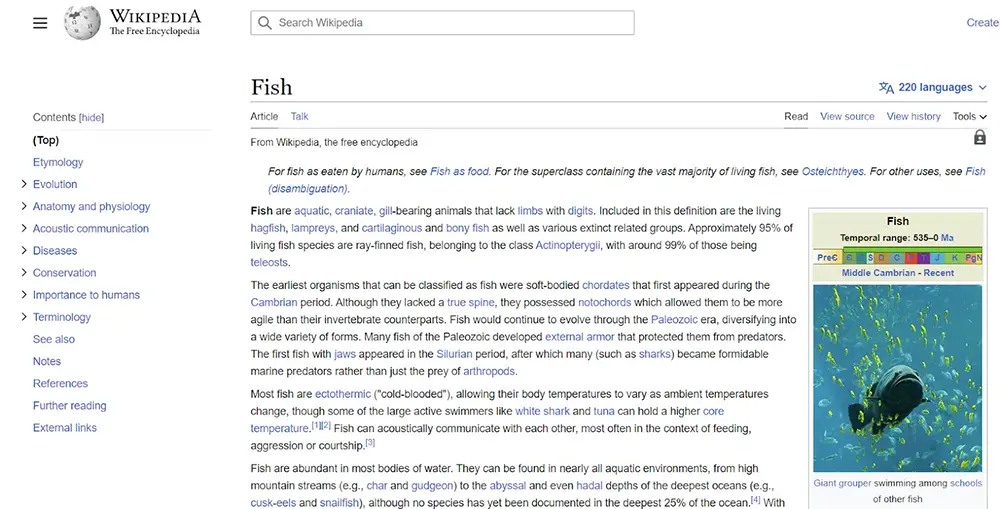
اگرچه ویکیپدیا اطلاعات زیادی درباره موضوعات مختلف دارد اما نمیتواند تمام جنبهها و جزئیات یک موضوع را پوشش دهد و منبعی جامع به حساب نمیآید. در واقع ویکیپدیا تنها بخشی از دانش موجود درباره یک موضوع را در اختیار کاربران قرار میدهد.
انتیتی (Entity) یا موجودیت چیست؟
موجودیت Entity به موضوع یا چیزی گفته میشود که به طور منحصربفرد قابل شناسایی باشد. موجودیتها را میتوان با نام، نوع، ویژگیها و ارتباطشان با سایر موجودیتها تعریف کرد. تنها زمانی یک شیء به عنوان موجودیت شناخته میشود که در فهرست موجودیتها (entity catalog) وجود داشته باشد.
فهرستهای موجودیت به هر موجودیت یک شناسه منحصربفرد اختصاص میدهند. اگر واژه یا عبارتی در فهرست وجود نداشته باشد، لزوماً به معنای موجودیت نبودن آن نیست، اما معمولاً وجود یک موضوع در فهرست نشانگر موجودیت بودن است.
ویکیپدیا تنها یک منبع برای شناسایی موجودیتها است و وجود یا عدم وجود یک مطلب در ویکیپدیا به معنای موجودیت بودن یا نبودن قطعی آن نیست. با این حال، ویکیپدیا به دلیل داشتن پایگاه داده بزرگی از موجودیتها، بیشتر با همین موضوع شناخته میشود. وقتی صحبت از موجودیت به میان میآید، هر پایگاه داده یا فهرستی که حاوی اطلاعات ساختاریافته در مورد موجودیتها باشد، میتواند مبنای تعریف و شناسایی موجودیتها قرار گیرد. موجودیتها معمولاً شامل اشخاص، مکانها و اشیاء هستند اما ایدهها و موجودیتها انتزاعی نیز میتوانند بعنوان موجودیت در نظر گرفته شوند.
چند نمونه از فهرستهای موجودیت:
- ویکیپدیا (Wikipedia): دائرةالمعارف آنلاین که حاوی مقالات متعددی درباره موجودیتهای مختلف است.
- ویکیداده (Wikidata): پایگاه داده ساختاریافته اطلاعات ویکیپدیا
- دیبیپدیا (DBpedia): پایگاه دادهای که اطلاعات ساختاریافتهای از ویکیپدیا استخراج میکند.
- فریبیس (Freebase): پایگاه دادهای حاوی اطلاعات درباره موجودیتها که توسط گوگل توسعه یافتهاست.
- یاگو (Yago): پایگاه داده بزرگی از اطلاعات ساختاریافته درباره موجودیتها.
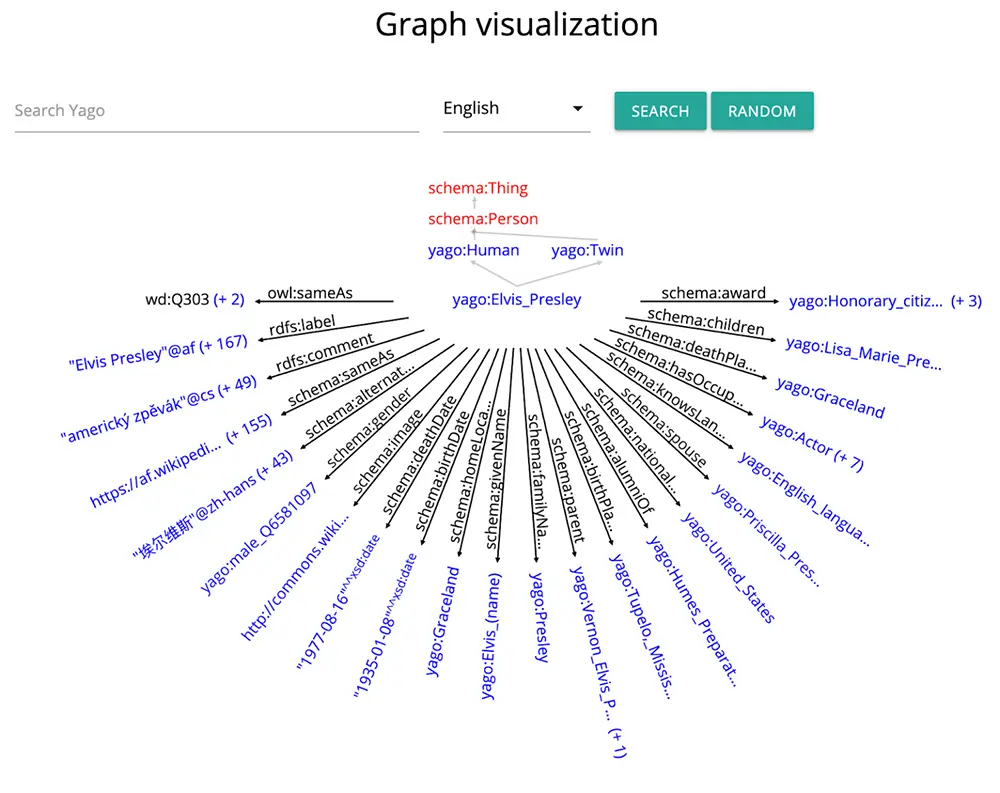
موجودیتها Entities به پر کردن شکاف بین دادههای ساختارنیافته و ساختاریافته (unstructured and structured data) کمک میکنند و میتوانند برای غنیسازی معنایی متون ساختارنیافته مورد استفاده قرار گیرند، در حالی که منابع متنی میتوانند برای استخراج موجودیتها و ذخیرهسازی آنها در پایگاهدادهها مورد استفاده قرار گیرند. بنابراین موجودیتها پل ارتباطی بین این دو نوع داده هستند و باعث ارتباط و تعامل بین آنها میشوند.
شناسایی ارجاعات به موجودیتها در متن و مرتبط کردن آنها با مدخل متناظرشان در پایگاهداده، به عنوان “لینکدهی موجودیت” (entity linking) شناخته میشود. موجودیتها باعث درک بهتر معنای متن، هم برای انسان و هم برای ماشین میشوند. اگرچه انسانها با توجه به بافت میتوانند ابهام موجودیتها را حل کنند، اما این مسئله برای ماشینها چالشبرانگیز است. مدخل هر موجودیت در پایگاهداده، خلاصهای از آنچه درباره آن میدانیم را ارائه میدهد.
با توجه به تغییرات مداوم دنیا و ظهور حقایق و اطلاعات جدید، پیگیری این تغییرات و بهروز نگه داشتن اطلاعات موجودیتها در پایگاهدادهها نیازمند تلاش مستمر ویراستاران و مدیران محتوا است که کار دشواری در مقیاس بزرگ است. با تحلیل متون حاوی ارجاعات موجودیتها، میتوان فرآیند یافتن اطلاعات و حقایق جدید یا نیازمند بهروزرسانی را تسهیل نموده یا حتی کاملاً به صورت خودکار درآورد. محققان به این مسئله به عنوان “مسئله غنیسازی پایگاه داده” اشاره میکنند که همین دلیل اهمیت لینکدهی به موجودیتها است.
موجودیتها Entities باعث درک معنایی نیاز اطلاعاتی کاربر و محتوای سند میشوند. آنها نیاز کاربر را همانطور که با عبارت جستجو بیان شده و همچنین محتوای سند را به شکل موجودیت ارائه میکنند. بنابراین میتوان از موجودیتها برای بهبود نمایش عبارت جستجو و یا محتوای سند استفاده کرد. موجودیتها ابزاری مفید برای درک بهتر نیاز کاربر و محتوا و بهبود فرایند جستجو هستند و در واقع درک معنایی را تسهیل میکنند.
در یک مقاله پژوهشی مرتبط با موجودیتها، نویسنده حدود ۱۶۰ نوع موجودیت را شناسایی کرده است که در اینجا دو تصویر از فهرست انواع موجودیتها آورده شده است.

گرچه برخی انواع موجودیتها آسانتر تعریف میشوند، اما مفاهیم (concepts) و ایدهها (ideas) نیز جزء موجودیتها محسوب میشوند. با این تفاوت که بسیار سخت و پیچیده هستند و گوگل نمیتواند به تنهایی آنها را به خوبی درک کند و صرفاً با یک صفحه، موجودیتها مبهم را نمیتوان به گوگل آموزش داد. درک موجودیتهای پیچیدهای مثل مفاهیم و ایدهها توسط ماشینها، مستلزم ایجاد محتوای گسترده و بلند مدت است.
تاریخچه گوگل در زمینه موجودیتها
در تاریخ ۱۶ ژوئیه ۲۰۱۰، گوگل سایت Freebase را خریداری کرد. این خرید اولین گام مهم گوگل بود که منجر به ایجاد سیستم فعلی جستجوی موجودیتها شد. با خرید Freebase، گوگل به یک پایگاه داده بزرگ ساختاریافته در مورد موجودیتها دسترسی پیدا کرد که نقطه شروعی برای توسعه قابلیتهای موجودیتمحور موتور جستجوی گوگل بود.
پس از سرمایهگذاری در ،Freebase گوگل دریافت که Wikidata گزینه بهتری برای پایگاه داده موجودیتهاست و سعی کرد Freebase را با آن ادغام کند که این کار دشوارتر از حد انتظار بوده است.

پنج پژوهشگر گوگل مقالهای با عنوان “از Freebase به Wikidata : مهاجرت بزرگ” نوشتند. نکات کلیدی این مقاله عبارتند از:
- پایگاه داده Freebase بر پایه مفاهیم اشیاء، واقعیتها، انواع و ویژگیها بنا شده است. هر شیء در Freebase دارای یک شناسه ثابت به نام mid (مخفف Machine ID) است.
- مدل دادهای Wikidata بر مبنای مفاهیم آیتم (item) و توضیح (statement) طراحی شده است. هر آیتم نمایانگر یک موجودیت است و دارای یک شناسه ثابت به نام qid میباشد. همچنین ممکن است هر آیتم دارای برچسبها، شرح و توضیحات و نامهای مترادف به زبانهای مختلف باشد. علاوه بر این، آیتمها حاوی توضیحات و پیوندهای بیشتری به صفحات مرتبط با آن موجودیت در سایر پروژههای ویکیمدیا از جمله ویکیپدیا هستند. در مقابل، بیانیههای Wikidata به دنبال کدگذاری حقایق و واقعیتها نیستند بلکه ادعاهایی از منابع مختلف را نمایش میدهند که ممکن است با هم در تناقض باشند…
موجودیتها در پایگاههای داده تعریف میشوند، اما گوگل هنوز باید دانش موجودیت خود را برای دادههای ساختارنیافته (مانند متون وبلاگها) ایجاد میکرد. بدین منظور، گوگل با همکاری شرکتهای بینگ و یاهو، پروژه Schema.org را راهاندازی کرد تا این کار را انجام دهد.
گوگل دستورالعملهایی برای استفاده از Schema ارائه کرده است تا مدیران سایتها بتوانند با بهکارگیری این ابزارها، به گوگل در درک بهتر محتوای صفحات کمک کنند. نباید فراموش کرد که گوگل میخواهد بجای تمرکز صرف بر رشتههای متنی، روی درک موجودیتها و ارتباط میان آنها تمرکز کند.
به گفته گوگل: “مدیران سایت میتوانند با ارائه دادههای ساختاریافته در صفحه، به گوگل در درک معنای محتوای صفحه کمک نمایند. دادههای ساختاریافته، فرمت استانداردی برای ارائه اطلاعات درباره یک صفحه و دستهبندی محتوای آن است. به عنوان مثال، در صفحه دستور پخت غذا، میتوان اطلاعاتی مانند مواد لازم، زمان و دمای پخت، میزان کالری و غیره را به صورت ساختاریافته ارائه کرد تا گوگل بهتر بتواند معنای صفحه را دریابد.”
گوگل در ادامه بیان میدارد: “باید تمام ویژگیهای ضروری یک شیء را مشخص کنید تا آن شیء شرایط نمایش غنیسازی شده در نتایج جستجوی گوگل را داشته باشد. به طور کلی، تعریف ویژگیهای توصیهشده بیشتر میتواند احتمال نمایش اطلاعات شما با فرمت غنیسازی شده در نتایج جستجو را افزایش دهد. با این حال، مهمتر این است که تعداد کمتری ویژگی توصیهشده را به طور کامل و دقیق ارائه کنید تا اینکه تلاش کنید تمام ویژگیهای توصیهشده را حتی با دادههای ناقص، نادرست یا با فرمت بد ارائه دهید.”
درباره ابزار Schema میتوان بیشتر صحبت کرد، اما کافی است بگوییم ابزاری بسیار عالی برای سئوکاران و متخصصانی است که میخواهند محتوای صفحات را برای موتورهای جستجو شفافسازی کنند. آخرین قطعه از پازل دانش موجودیتهای گوگل، وبلاگ اعلامیه گوگل با عنوان “بهبود جستجو برای 20 سال آینده” است.
ایده اصلی پشت این اعلامیه، مرتبط بودن و کیفیت اسناد است. اولین روشی که گوگل برای تعیین محتوای یک صفحه به کار میبرد، تماماً متمرکز بر کلمات کلیدی بود. سپس گوگل لایههای موضوعی (topic layers) را به جستجو اضافه کرد. این لایه با کمک گرافهای دانش و استخراج و ساختاردهی سیستماتیک دادهها در سراسر وب امکانپذیر شد. دستاورد این کار سیستم جستجوی فعلی است. گوگل در کمتر از ۱۰ سال از ۵۷۰ میلیون موجودیت به ۸ میلیارد موجودیت و از ۱۸ میلیارد فکت به ۸۰۰ میلیارد فکت دست یافته است. با رشد این اعداد، جستجوی موجودیت بهبود مییابد.
مدل سئوی موجودیت Entity SEO چگونه نسبت به مدلهای قدیمیتر، جستجوی بهبود یافته است؟
مدلهای قدیمی بازیابی اطلاعات (IR) که مبتنی بر کلمات کلیدی هستند، محدودیت ذاتی در بازیابی اسناد مرتبطی دارند که هیچ تطابق مستقیم واژگانی با عبارت جستجو شده ندارند. این مدلها تنها میتوانند اسنادی را بازیابی کنند که شامل کلمات کلیدی مشخص شده در عبارت جستجو هستند. به عنوان مثال اگر با استفاده از ctrl+f بخواهید متنی را در یک صفحه پیدا کنید، از همان اصول مدلهای سنتی بازیابی اطلاعات استفاده میکنید.
حجم انبوهی از دادهها هر روز در وب منتشر میشود. درک معنای هر کلمه، پاراگراف، مقاله و محتوای وبسایت برای گوگل امکانپذیر نیست. به جای این کار، موجودیتها ساختاری را فراهم میکنند که گوگل میتواند با بهرهگیری از آن، بار محاسباتی را کاهش دهد و در عین حال درک بهتری از موجودیتها داشته باشد. موجودیتها به گوگل اجازه میدهند به جای تجزیه و تحلیل تمام متن، تنها روی بخشهای کلیدی و ساختاریافتهای از اطلاعات متمرکز شود که درک معنایی آنها مهم است.
“روشهای بازیابی اطلاعات مبتنی بر موجودیت، با هدف غلبه بر چنین چالشهایی در بازیابی متن، از ساختارهایی مانند واژگان کنترل شده (دیکشنری و فرهنگ جامع)، انتولوژی و موجودیتهای استخراج شده از مخازن دانش بهره میگیرند. این ساختارها باعث میشوند درخواستها و مدارک از لحاظ موجودیت غنیتر شده و در یک فضای معنایی و موجودیت سطح بالاتر قرار گیرند. در نتیجه، تطابق بهتری بین درخواستها و مدارک برقرار میشود و بازیابی دقیقتر و مرتبطتری حاصل میگردد.” برگرفته از کتاب جستجوی موجودیتمحور ، بخش ۸.۳
Krisztian Balog، نویسنده این کتاب مرجع در مورد موجودیتها، سه راهکار برای بهبود مدل سنتی بازیابی اطلاعات پیشنهاد میکند:
- راهکار مبتنی بر توسعه: که در آن از موجودیتها به عنوان منبعی برای توسعه و غنیسازی درخواست کاربر با اصطلاحات مختلف استفاده میشود.
- راهکار مبتنی بر تصویرسازی: که در آن ارتباط بین درخواست کاربران و سند از طریق تصویرسازی آنها بر روی فضای نهفتهای از موجودیتها درک میشود.
- راهکار مبتنی بر موجودیت: که در آن بازنمایی معنای صریحی از درخواستهای کاربران و اسناد در فضای موجودیتها به دست میآید تا بازنمایی مبتنی بر اصطلاح را تقویت کند.
هدف اصلی این سه راهکار، ارائه نتایج غنیتر و کاملتر از نیاز اطلاعاتی کاربر است. این کار از طریق شناسایی موجودیتهایی انجام میشود که ارتباط قوی و تنگاتنگی با درخواست کاربر دارند. با شناسایی این موجودیتها و استفاده از آنها در نتایج عبارت جستجو شده توسط کاربر، میتوان نتایج غنیتر و نزدیکتر به نیاز واقعی اطلاعاتی کاربر به دست آورد. این امر منجر به بازیابی دقیقتر و مرتبطتر اطلاعات خواسته شده توسط کاربر خواهد شد.
بالوگ سپس شش الگوریتم را معرفی میکند که با روشهای مبتنی بر تصویرسازی برای نگاشت موجودیتها مرتبط هستند (روشهای مبتنی بر تصویرسازی مربوط به تبدیل موجودیتها به فضای سهبعدی و اندازهگیری بردارها با استفاده از هندسه صورت میگیرد). شش الگوریتمی که بالوگ معرفی میکند، الگوریتمهایی هستند که در این نوع روشها برای نگاشت موجودیتها و اندازهگیری ارتباطات بین آنها به کار میروند.
- تحلیل معنایی صریح (ESA): در این الگوریتم، معنای یک واژه با استفاده از یک بردار توصیف میشود که این بردار، قدرت ارتباط آن واژه را با موجودیتها استخراج شده از ویکیپدیا ذخیره میکند. به عبارت دیگر، بردار نشان میدهد که آن واژه تا چه حد با هر یک از موجودیتها ویکیپدیا مرتبط است. این کار باعث میشود معنای واژه به صورت کمی و بر اساس ارتباط آن با موجودیتهای دیگر توصیف شود.
- مدل فضای نهان موجودیت (LES): این الگوریتم مبتنی بر یک چارچوب احتمالی مولد است. این مدل امتیاز بازیابی سند را بر اساس ترکیب خطی از امتیاز مرتبط بودن آن سند با موجودیتهای نهفته و امتیاز مرتبط بودن آن با خود عبارت جستجو شده محاسبه میکند.
- EsdRank: یک الگوریتم برای رتبهبندی اسناد است که از ترکیبی از ویژگیهای جستار-موجودیت و موجودیت-سند استفاده میکند. این ویژگیها به ترتیب موجودیتها تصویرسازی جستار و تصویرسازی سند را در مدل LES منعکس میکنند. EsdRank از یک چارچوب یادگیری تشخیصی استفاده میکند که اجازه میدهد سیگنالهای اضافی مانند محبوبیت موجودیت یا کیفیت سند به راحتی در الگوریتم لحاظ شوند.
- رتبهبندی معنایی صریح (ESR): این مدل با هدف انجام تطابق متعادل بین درخواست کاربر و اسناد در فضای موجودیتها، از اطلاعات رابطهای موجود در گرافهای دانش استفاده میکند. به عبارت دیگر، این الگوریتم با بهرهگیری از اطلاعات گراف دانش در مورد روابط بین موجودیتها، قادر است تطابقها و ارتباطات ضمنی و معنایی بین عبارات جستجو شده توسط کاربر و اسناد را در سطح موجودیتها شناسایی کند. به این ترتیب، تطابقهای معنایی فراتر از سطح واژگان حاصل میشود.
- چارچوب دووجهی واژه-موجودیت: این الگوریتم تعاملات بین دو نوع نمایش متن یعنی مبتنی بر واژه و مبتنی بر موجودیت را در نظر میگیرد. این چارچوب با در نظر گرفتن چهار نوع تطابق بین جستار و سند شامل تطابق واژگان جستار با واژگان سند؛ تطابق موجودیتهای جستار با واژگان سند؛ تطابق واژگان جستار با موجودیتهای سند؛ و تطابق موجودیتهای جستار با موجودیتهای سند، سعی در لحاظ کردن تطابقها در سطوح مختلف واژگانی و معنایی دارد.
- مدل رتبهبندی مبتنی بر توجه: این مدل پیچیدهترین مدل در بین سایر مدلهای مبتنی بر موجودیت برای رتبهبندی اسناد است و توضیح کامل این الگوریتم نیازمند ورود به جزئیات فنی و پیچیده است.
بالوگ در کتاب خود این گونه به این موضوع پرداخته است : “مجموعاً چهار ویژگی مبتنی بر توجه طراحی شده است که برای هر موجودیت عبارت جستجو شده استخراج میشوند. ویژگیهای ابهام موجودیت قرار است خطر مرتبط با حاشیهنویسی موجودیت را مشخص کنند. این ویژگیها عبارتند از: (۱) آنتروپی احتمال پیوند شکل سطحی به موجودیتهای مختلف (مثلاً در ویکیپدیا)؛ (۲) اینکه آیا موجودیت تشریح شده معمولترین معنا برای فرم سطحی است (یعنی بیشترین امتیاز مشترک را دارد)؛ (۳) تفاوت در امتیازات مشترک بین محتملترین و دومین گزینه محتمل برای فرم سطحی داده شده. (۴) نزدیکی که به عنوان شباهت کسینوسی بین موجودیت جستار و خود جستار در یک فضای جانمایی شده تعریف میشود. به طور خاص، یک مدل جانمایی مشترک واژه-موجودیت با استفاده از الگوریتم skip-gram روی یک مجموعه داده آموزش داده میشود. در این مجموعه داده آموزشی، موجودیتهای ارجاع شده با شناسههای موجودیت مربوط به خودشان جایگزین شدهاند. سپس بردار جانمایی مربوط به جستار، به عنوان مرکز ثقل (میانگین) بردارهای جانمایی واژگان تشکیل دهنده عبارت جستجو شده در نظر گرفته میشود.”
آشنایی سطحی با این شش الگوریتم که محوریت آنها بر موجودیتهاست، مهم است. لازم نیست به جزئیات و عمق الگوریتمها پرداخته شود؛ صرفاً داشتن تصویر کلی از این الگوریتمها و رویکرد آنها کافی است.
نکته اصلی و کلیدی این است که دو رویکرد اصلی برای استفاده از موجودیتها در بازیابی اطلاعات وجود دارد:
- تصویرسازی و نگاشت اسناد به یک لایه یا فضای نهان از موجودیتها
- حاشیهنویسی و برچسبگذاری صریح موجودیتها در درون متن اسناد
این دو رویکرد اصلی، محور اغلب الگوریتمهای مبتنی بر موجودیت در بازیابی اطلاعات هستند.
سه نوع ساختار داده
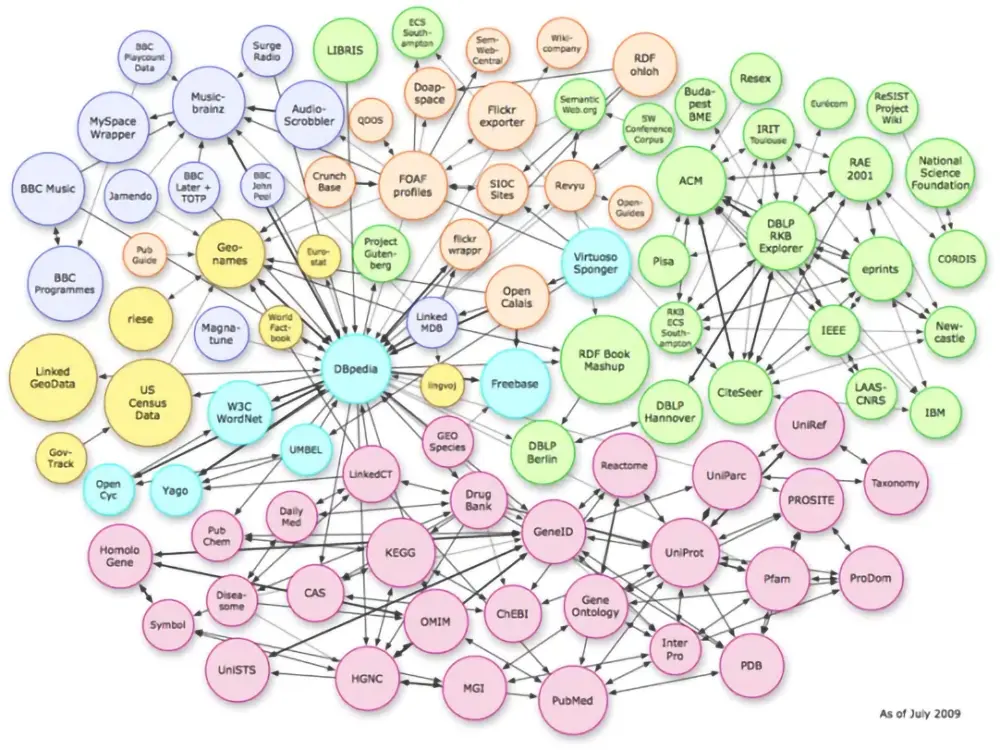
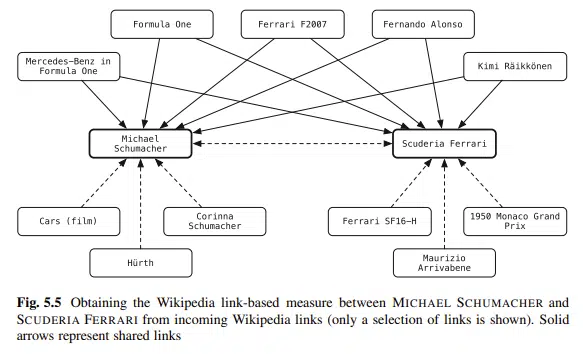
تصویر زیر روابط پیچیده بین موجودیتها در فضای برداری را نشان میدهد. اگرچه این مثال ارتباطات در یک گراف دانش را نشان میدهد، اما همین الگو در سطح صفحات وب نیز بین موجودیتها وجود دارد و قابل بازتولید و مدلسازی است.
برای درک بهتر موجودیت موجودیتها، شناخت سه نوع ساختار دادهای که الگوریتمها از آنها استفاده میکنند، ضروری است:
- هنگام استفاده از توصیفات موجودیتهای ساختارنیافته، باید مراجع و ارجاعات به سایر موجودیتها در متن شناسایی شده و ابهامزدایی گردند. سپس لبههای جهتدار (هایپر لینکها) از هر موجودیت به تمام موجودیتهای دیگری که در توصیف آن موجودیت به آنها اشاره شده است، اضافه میگردد.
- در حالت نیمهساختاریافته (مانند ویکیپدیا)، احتمال دارد که لینکهای سایر موجودیتها به طور صریح و واضح ارائه شده باشند.
- هنگام کار با دادههای ساختاریافته، سهتاییهای RDF یک گراف (مانند گراف دانش) را تعریف میکنند. به طور خاص، موضوعات و اشیاء (URIs) گره هستند و گزارهها لبه هستند.
مشکل اصلی حالت نیمهساختاریافته در محاسبه امتیاز بازیابی اطلاعات این است که اگر یک سند برای یک موضوع خاص طراحی نشده باشد و محتوای آن پراکنده باشد، امتیاز بازیابی آن میتواند به دلیل وجود بافتهای مختلف در سند، تضعیف شود. در نتیجه رتبه این سند نسبت به سایر اسناد متنی کاهش پیدا میکند. دلیل این مسئله، وجود روابط واژگانی ضعیف و نامناسب و همچنین فاصله نامناسب بین واژگان در سند است.
واژگان مرتبط که مکمل یکدیگر هستند، باید در نزدیکی یکدیگر و در یک پاراگراف یا بخش از سند استفاده شوند تا بافت موضوعی به صورت واضحتری به سیستم منتقل شود و در نتیجه امتیاز بازیابی اطلاعات آن سند افزایش یابد. بنابراین، استفاده از واژگان مرتبط در کنار هم و در یک بافت مشخص، باعث میشود موضوع سند واضحتر شده و امتیاز بازیابی بهبود یابد.
استفاده از ویژگیها و ارتباطات موجودیتها میتواند بازیابی را تا ۲۰ درصد بهبود بخشد. همچنین استفاده از اطلاعات نوع موجودیت میتواند بازیابی را تا بیش از ۱۰۰ درصد نسبت به عدم استفاده از موجودیتها بهبود بخشد.
حاشیهنویسی یا برچسبگذاری اسناد با استفاده از موجودیتها میتواند برای اسناد ساختارنیافته یک ساختار ایجاد کند که این امر میتواند با اطلاعات جدید در مورد موجودیتها باعث غنیسازی پایگاههای دانش شود.
استفاده از ویکیپدیا به عنوان مدل موجودیت سئو
ساختار صفحات ویکیپدیا
۱- عنوان
۲- متن مقدماتی یا lead
- پیوندهای ابهامزدایی
- جعبه اطلاعات
- متن مقدماتی
۳- فهرست مطالب
۴- محتوای اصلی
۵- ضمایم و مطالب انتهایی
- منابع و یادداشتها
- پیوندهای خارجی
- دستهبندیها
اکثر مقالات ویکیپدیا شامل یک متن مقدماتی یا “لید” هستند که خلاصهای کوتاه از محتوای مقاله است ( معمولاً بیش از چهار پاراگراف نیست). این بخش باید به گونهای نوشته شود که نظر کاربر را جلب کرده و علاقهمندی خواننده را به مطالعه مقاله برانگیزد.
اولین جمله و پاراگراف ابتدایی اهمیت ویژهای دارند. اولین جمله میتواند به عنوان تعریفی از موجودیت توصیف شده در مقاله در نظر گرفته شود. پاراگراف ابتدایی نیز تعریفی اجمالی از موضوع مقاله ارائه میدهد.
ارزش لینکها فراتر از اهداف پیمایشی (navigational) است؛ آنها روابط معنایی بین مقالات را ثبت میکنند. علاوه بر این، انکر تکستها (anchor text) یک منبع غنی از انواع (variants) نام موجودیت هستند. پیوندهای ویکیپدیا میتوانند میان سایر کاربردها برای کمک به شناسایی و ابهامزدایی ارجاعات موجودیتها در متن استفاده شوند. خلاصهای از ویژگیهای اصلی صفحات ویکیپدیا که حاوی اطلاعات کلیدی ساختاریافته درباره موجودیتها هستند، به شرح زیر است:
- خلاصهای از واقعیتهای کلیدی درباره موجودیت در جعبه اطلاعات
- معرفی کوتاه و اجمالی
- پیوندهای داخلی به اولین ارجاع هر موجودیت یا مفهوم (concept)
- ذکر همه مترادفهای محبوب برای یک موجودیت
- تعیین دستهبندی صفحه
- الگوی پیمایشی
- منابع و مراجع
- ابزارهای ویژه برای تجزیه و تحلیل صفحات ویکی
- انواع مولتی مدیا
نحوه بهینهسازی سیستمهای مختلف برای کار با انتیتی ها
در ادامه ملاحظات اساسی بهینهسازی موجودیتها برای موتورهای جستجو ارائه شده است:
- گنجاندن واژگان و عبارات مرتبط معنایی با موضوع در یک صفحه
- فراوانی واژگان و عبارات در یک صفحه
- سازماندهی موجودیتها در یک صفحه
- گنجاندن دادههای ساختارنیافته، نیمه ساختاریافته و ساختاریافته در یک صفحه
- افزودن جفتهای موضوع-گزاره-شی (SPO)
- ارائه اسناد وب در یک سایت که مانند صفحات یک کتاب عمل میکنند
- سازماندهی اسناد وب در صطح صفحه و وبسایت
- گنجاندن موجودیتهای در یک سند وب که ویژگیهای شناخته شدهای از موجودیتها هستند
نکته مهم: وقتی تمرکز یک پایگاه دانش بر روی روابط و ارتباطات بین موجودیتها باشد، آن پایگاه دانش را معمولاً گراف دانش مینامند.
از آنجایی که قصد و نیت کاربر در کنار ثبت وقایع جستجو و سایر بخشهای بافت مورد تحلیل قرار میگیرد، یک عبارت جستجوی یکسان از سوی دو کاربر مختلف میتواند نتایج متفاوتی تولید کند. کاربران میتوانند با یک درخواست کاملاً یکسان، قصد و نیت متفاوتی داشته باشند. بنابراین، تحلیل قصد و نیت کاربر در کنار سایر عوامل بافتی میتواند منجر به نتایج شخصیسازی شدهای حتی برای یک درخواست یکسان گردد.
اگر صفحه شما هر دو نوع قصد و نیت را پوشش میدهد، آنگاه صفحه شما کاندید بهتری برای رتبهبندی وب است و میتوانید از ساختار پایگاههای دانش برای هدایت الگوهای درخواست-قصد (query-intent) خود استفاده کنید. پوشش دادن انواع مختلف قصد و نیت کاربران در یک صفحه، میتواند باعث بهبود رتبه آن صفحه شود.
قابلیتهایی همچون “سایرین همچنین پرسیدهاند”، “مردم همچنین جستجو کردهاند” و “تکمیل خودکار” در موتورهای جستجو، ارتباط معنایی با درخواست جستجوی کاربر دارند. این ویژگیها یا به عمق بیشتر در همان جهت جستجوی فعلی میپردازند یا کاربر را به سمت جنبه دیگری از موضوع جستجو هدایت میکنند. این ویژگیها با ارتباط معنایی با درخواست کاربر، به او کمک میکنند تا جستجویش را گستردهتر و عمیقتر انجام دهد.
اکنون که موجودیت این موضوع را درک کردهایم، چگونه میتوانیم آن را در جهت بهینهسازی یک سیستم یا فرآیند به کار گیریم؟
اسناد و محتوا باید تا حد امکان حاوی تنوع و تغییرات مختلف قصد جستجو باشند. وبسایت شما باید شامل تمام تغییرات احتمالی قصد جستجو برای مجموعه یا خوشه مربوطه باشد. پوشش حداکثری تنوع قصد جستجو در اسناد و صفحات، مبنای خوشهبندی و گروهبندی آنهاست. خوشهبندی بر پایه سه نوع تشابه استوار است:
- تشابه واژگانی
- تشابه معنایی
- تشابه کلیک
پوشش موضوع
دستورالعمل نوشتن محتوایی جامع در مورد یک موضوع به این شکل است:
توضیح موضوع ← فهرست ویژگیها و خصوصیات ← اختصاص بخشی به هر خصوصیت ← لینکدهی هر بخش به مقالهای که کاملاً به آن موضوع اختصاص دارد← شناسایی مخاطبان هدف و تعیین تعاریف بخشهای فرعی ← بررسی نکاتی که باید مدنظر قرار گیرند ← بیان مزایا ← بیان مزایای تکمیلی و اصلاحی ← توضیح عملکرد موضوع ← چگونگی دستیابی به موضوع ← نحوه انجام آن ← چه کسانی قادر به انجام آن هستند؟ ← لینکدهی مجدد به همه دستهبندیها

گوگل ابزاری ارائه میدهد که امتیاز یا نمرهای به نام Salience Score به محتوا اختصاص میدهد. این نمره نشاندهنده میزان برجستگی و اهمیت محتوا از دیدگاه گوگل است. با داشتن این نمره میتوان درک کرد که گوگل تا چه حد اهمیت و ارزش برای قسمتهای مختلف محتوا قائل است.
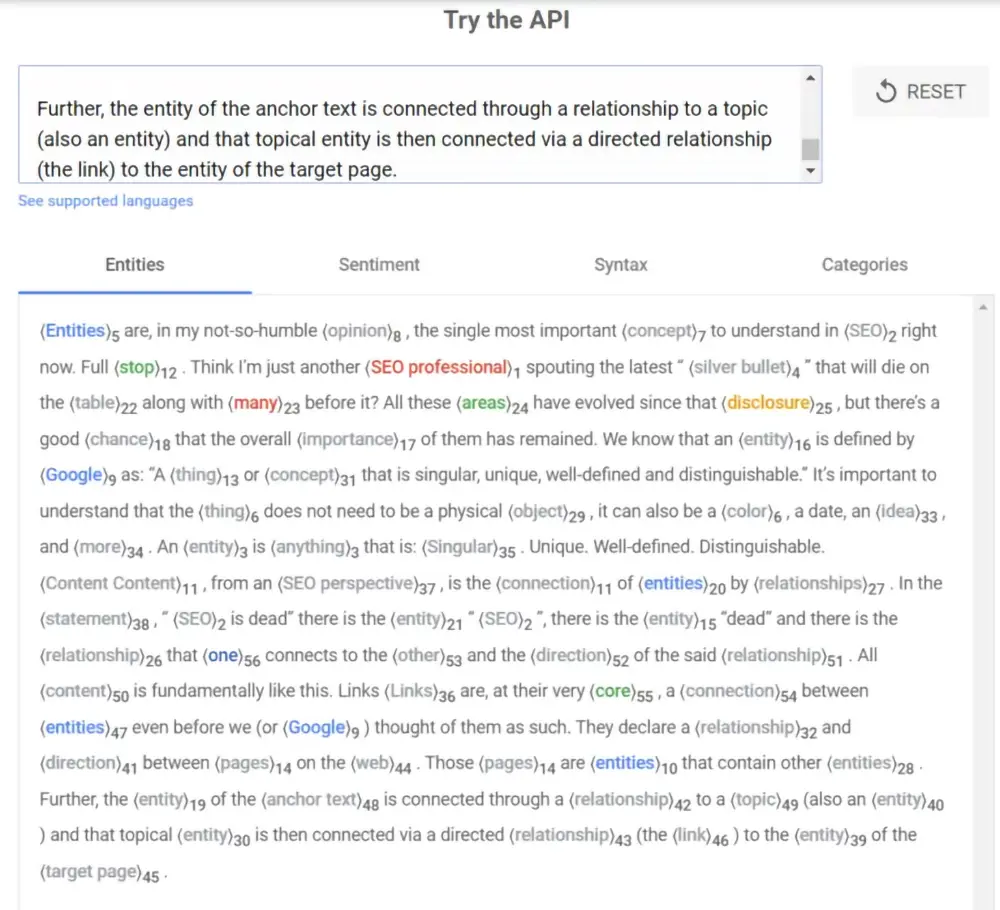
مثال بالا از یک مقاله در مورد موجودیتها در سال ۲۰۱۸ بر گرفته شده است.
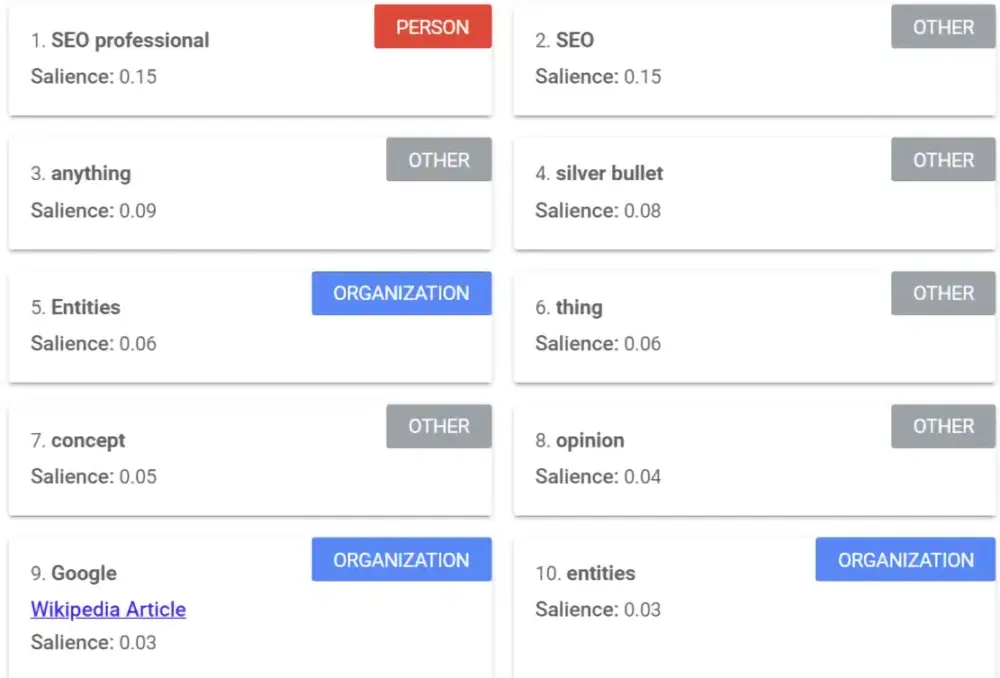
در این مثال، موجودیتهای فرد (person)، سازمان (organization) و سایر (other) قابل مشاهده هستند.
زمانی که صحبت از یک موجودیت به میان میآید، هر واژه، جمله و پاراگراف اهمیت مییابد. نحوه سازماندهی افکار و اندیشهها میتواند درک و شناخت گوگل از محتوای شما را تغییر دهد. بنابراین موضوع اصلی، اهمیت نوشتن دقیق و سازماندهی مناسب مطالب درباره یک موجودیت برای بهبود درک موتور جستجو از محتواست.
ممکن است واژه کلیدی مرتبط با سئو را در محتوای خود بگنجانید، اما آیا گوگل آن واژه کلیدی را به همان شکلی که شما میخواهید درک میکند؟ صرف استفاده از یک واژه کلیدی خاص، تضمینکننده درک صحیح آن توسط موتور جستجو نیست. بلکه باید محتوا به گونهای نوشته شود که موجودیت مورد نظر به طور کامل منتقل گردد.
یک یا دو پاراگراف را در ابزار (ابزار سنجش برجستگی محتوای گوگل) قرار دهید و با تغییر سازماندهی و اصلاح آن، ببینید چگونه امتیاز برجستگی آن افزایش یا کاهش پیدا میکند. با آزمایش محتوا و تغییر ساختار و واژگان آن، اثر این تغییرات بر نمره برجستگی مشاهده و بررسی کنید.
این تمرین “ابهامزدایی” (disambiguation) نام دارد و ابهامزدایی واژگان و اصطلاحات برای موجودیتها اهمیت زیادی دارد، چون زبان ذاتاً ابهام دارد و ما باید سعی کنیم معانی واژگان را برای موتورهای جستجو مانند گوگل کاملاً روشن و کمابهام بیان کنیم تا به درستی درک شود.
روشهای مدرن ابهامزدایی برای تشخیص صحیح موجودیتها، از سه نوع شاهد و مدرک استفاده میکنند:
- اول اینکه اهمیت و وزن قبلی موجودیتها و واژههایی که به آنها ارجاع داده میشود را در نظر میگیرند.
- دوم اینکه میزان تشابه معنایی و متنی بین متن اطراف یک ارجاع به موجودیت و خود آن موجودیت را محاسبه میکنند.
- سوم اینکه انسجام کلی بین تمام تصمیمگیریهای مربوط به لینکدهی موجودیتها در یک سند را در نظر میگیرند.
با در نظر گرفتن این شواهد مختلف، ابهامزدایی دقیقتری انجام میشود.
استفاده از Schema یکی از روشهای محبوب برای ابهامزدایی محتوا است. در این روش موجودیتها در وبلاگ به منابع و پایگاه دانش ساختاریافته لینک میشوند. بالوگ در این باره میگوید:
“لینکدهی موجودیتها در متن ساختارنیافته به یک پایگاه دانش ساختاریافته، میتواند به طور چشمگیری توانایی کاربران را در استفاده از اطلاعات افزایش دهد.”
توضیح مترجم: اینجاست که دادن لینک خارجی مثلا به ویکی پدیا در بلاگهای سایت معنی پیدا میکند اما برخی این کار را با کوسایتیشن توجیه میکنند که موضوعی اشتباه است و تعریف نادرستی از کوسایتیشن دارند بلکه لینک دادن به منابع بیرونی خصوصا متون ساختاریافتهای همچون ویکی پدیا به درک کامل و دقیقتر متن ما کمک میکند. یک مثال را در نظر بگیریم: فرض کنید صفحهای از سایت شما در مورد لیزر موهای زائد است و روی این کلمه شما بهینهسازی کردهاید. داخل متن شما کلمه لیزر را به صفحه ویکی پدیا لیزر ارجاع میدهید و تصویر میکنید که کار درستی انجام دادهاید که خود کلمه کلیدی تارگت را لینک ندادهاید، غافل از اینکه کلمه لیزر یک مفهوم علمی و گسترده است و گوگل را در شناخت متن شما گمراه میکند. پس اگر خود کلمه لیزر موهای زائد را لینک بدهید بهتر است و بهتر از آن این که کلمه خود را گستردهتر کنید و مثلا لیزر رفع موهای زائد را لینک بدهید که اتفاقا صفحه جامع و کاملی نیز در ویکی پدیا دارد.
به عنوان مثال، خوانندگان یک سند یا محتوا میتوانند با کلیک روی موجودیتها، اطلاعات زمینهای بیشتری در مورد آنها به دست بیاورند و به آسانی به موجودیتهای مرتبط دسترسی پیدا کنند. همچنین برچسبگذاری و شناسایی موجودیتها در متن، میتواند در مراحل بعدی مانند بازیابی اطلاعات و نمایش نتایج به کاربر، مورد استفاده قرار گرفته و باعث بهبود عملکرد بازیابی یا تسهیل تعامل بهتر کاربر با نتایج جستجو شود.
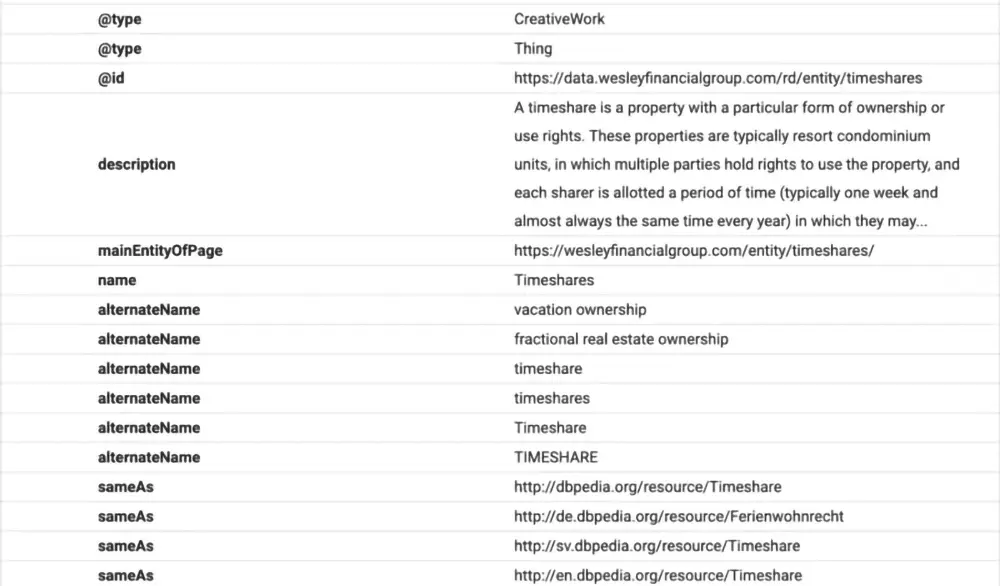
محتوای سوالات متداول که با استفاده از Schema برای موتور جستجوی گوگل ساختاردهی و برچسبگذاری شدهاست.
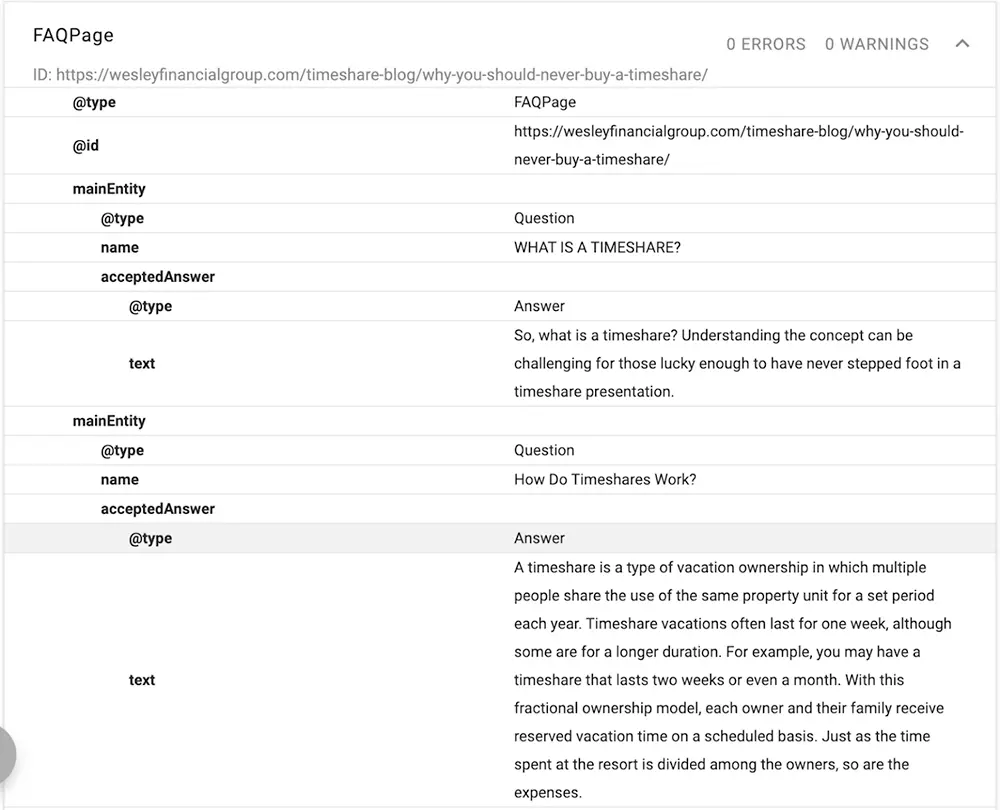
در این مثال Schema شامل توصیفی از متن، یک شناسه و اعلام موجودیت اصلی صفحه است.
یادآوری: گوگل برای درک بهتر ساختار و سلسلهمراتب اطلاعات در یک صفحه، نیاز به استفاده از عناوین یا تگ هدینگ H1 تا H6 دارد. پس برای بهینهسازی SEO، باید از این عناوین به درستی در ساختاردهی به محتوا استفاده کرد.
استفاده از Schema به گوگل امکان میدهد تا ارتباط بین متن یک صفحه و پایگاهدادههای ساختاریافته مرتبط را تشخیص دهد. همچنین Schema با فراهم کردن نامهای جایگزین و مترادف برای موجودیتها، به گوگل امکان میدهد تا روابط معنایی میان واژگان متفاوت اما مرتبط با یک موجودیت را تشخیص دهد.
وقتی با استفاده از Schema اقدام به بهینهسازی میکنید، در واقع برای NER (شناسایی اسامی موجودیتها named entity recognition ) که به آن شناسایی entity identification، استخراج entity extraction و دستهبندی موجودیت entity chunking هم گفته میشود، بهینهسازی میکنید. یعنی Schema بهینهسازی شده، به الگوریتمهای شناسایی و استخراج موجودیتها کمک میکند تا بهتر عمل کنند و موجودیتها را دقیقتر شناسایی و استخراج نمایند. ایده اصلی این است که طبق مراحل زیر برای بهبود شناسایی و درک موجودیتها تلاش کنیم:
- ابهامزدایی اسامی موجودیتها: تعیین معنای صحیح برای موجودیتهای دارای چند موجودیت در متن
- ویکیسازی(Wikification): لینکدهی به صفحات ویکیپدیای مرتبط با موجودیتها
- لینکدهی موجودیتها: لینک کردن موجودیتهای متن به موجودیتها در منابع ساختاریافته
با انجام این مراحل، ارتباطات و معانی موجودیتها بهتر درک شده و دقت سیستمها در شناسایی و دستهبندی آنها افزایش مییابد.
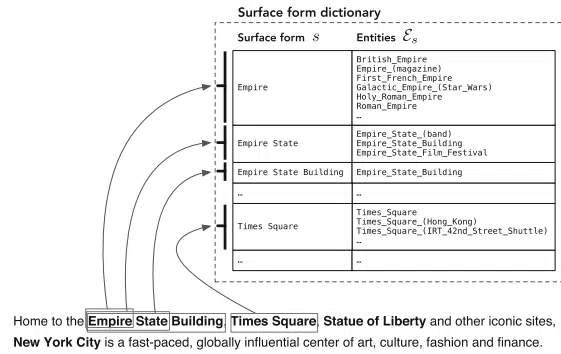
“ایجاد ویکیپدیا موجب تسهیل شناسایی و ابهامزدایی موجودیتها در مقیاس بزرگ شده است، زیرا ویکیپدیا فهرست جامعی از موجودیتها را گردآوری کرده است و همچنین منابع باارزش دیگری (مانند هایپرلینکها، دستهبندیها و صفحات تغییرمسیر و ابهامزدایی) را نیز فراهم میکند.” برگرفته از کتاب جستجوی موجودیتمحور.
چگونه فراتر از پیشنهادات ابزارهای سئو عمل کنیم؟
اکثر متخصصان سئو از ابزارهای سئوی داخلی (on-page) برای بهینهسازی صفحات استفاده میکنند که محدودیتهایی در شناسایی فرصتهای ایجاد محتوا و پیشنهاد عمق محتوا دارند و نمیتوان کاملاً به آنها متکی بود. اکثر این ابزارهای بهینهسازی، فقط نتایج برتر صفحات جستجو را جمعآوری کرده و بر اساس آن، الگو یا میانگینی را به عنوان توصیه بهینهسازی ارائه میکنند تا بتوانید از آنها الگوبرداری کنید. البته باید به خاطر داشته باشید که گوگل به دنبال اطلاعات تکراری و بازتولید شده نیست. صرفاً الگوبرداری از دیگران کافی نیست؛ بلکه باید محتوای ارزشمند و منحصربفرد تولید کرد تا وبسایت شما به یک مرجع معتبر و قابل اعتماد تبدیل شود.
توضیح ساده از نحوه برخورد گوگل با محتوای جدید به شرح زیر است:
وقتی سند یا محتوای جدیدی ارائه شود که به یک موجودیت خاصی اشاره میکند، گوگل محتوای جدید را بررسی میکند تا اگر اطلاعات تازهای در مورد یک موجودیت داشت، مدخل پایگاه دانش آن موجودیت را بهروزرسانی کند.
بالوگ در این باره مینویسد: “ما میخواهیم به ویراستاران کمک کنیم تا با شناسایی خودکار محتوای جدید (مقالات خبری، پستهای وبلاگ و غیره)، آنها را از آخرین تغییرات مدخلهای پایگاه دانش برای مجموعهای از موجودیتهای مورد علاقه ( موجودیتهایی که یک ویراستار خاص مسئول آنهاست) مطلع کنیم تا پایگاهدانش را بهروز نگه دارند.”
ارائه محتوای ارزشمند جدید که باعث بهروزرسانی پایگاههای دانش و بهبود شناسایی موجودیتها و قابلیت خزش (Crawlability) وبسایت شود، مورد توجه گوگل قرار میگیرد و منبع اصلی آن قابل ردیابی است. یعنی تغییرات اعمال شده در پایگاه دانش به سند اصلی یا وبسایت شما به عنوان منبع اولیه ارجاع داده میشود.
ارائه محتوای ارزشمند و عمیق در یک حوزه موضوعی خاص، میتواند باعث شود سایت شما در آن حوزه به عنوان یک مرجع معتبر شناخته شود. گوگل با تجزیه و تحلیل محتوا میتواند اطلاعات جدید و با ارزشی که توسط شما ارائه میشود را شناسایی کند. در صورت ارائه مداوم چنین اطلاعات باارزشی، میتوانید مرجعیت خود را نه بر اساس رتبه دامنه بلکه بر پایه پوشش عمیق موضوعی شکل دهید که بسیار ارزشمندتر است.
در رویکرد مبتنی بر سئوی موجودیت، محدود به هدفگذاری کلمات کلیدی بر اساس میزان جستجو نیستید. تنها کاری که لازم است انجام دهید اعتبارسنجی اصطلاح اولیه (به عنوان مثال “ماهیگیری با قلاب پروانهای”) است. سپس میتوانید با تکیه بر تفکر خلاقانه انسانی، بر تغییرات هدف جستجو متمرکز شوید و آنها را هدف قرار دهید.
برای مثال ماهیگیری با قلاب پروانهای، حداقل این موجودیتها باید در یک سایت خرید و فروش تجهیزات یا آموزش ماهیگیری پوشش داده شوند: گونههای ماهی، تاریخچه، مبدأ، توسعه، بهبودهای فناورانه، روشهای ماهیگیری با قلاب پروانهای، پرتاب قلاب، پرتاب اسپی، شکار ماهی قزلآلا با قلاب پروانهای، تکنیکهای ماهیگیری با قلاب پروانهای، ماهیگیری در آب سرد، شکار ماهی قزلآلا با قلاب خشک، قلابزنی ماهی قزلآلا، ماهیگیری قزلآلا در آبهای ساکن، بازی دادن قزلآلا، رهاسازی قزلآلا، ماهیگیری با قلاب پروانهای در آبهای شور، تجهیزات، قلابهای پردار و گرهها.
موضوعات بالا از صفحه ویکیپدیای ماهیگیری با قلاب پروانهای گرفته شدهاند. با وجود اینکه این صفحه مرور کلی خوبی از موضوعات ارائه میدهد، موضوعات و موجودیتها مرتبط معنایی را نیز میتوان به عنوان ایدههای جدید موضوعی اضافه کرد تا پوشش موضوعی گستردهتر شود.
برای موضوع “ماهی”، میتوان چندین موضوع اضافی از جمله ریشهشناسی، تکامل، آناتومی و فیزیولوژی، ارتباطات ماهیها، بیماریهای ماهیها، حفاظت، و اهمیت برای انسانها را اضافه نمود. آیا تاکنون کسی آناتومی ماهی قزلآلا را به اثربخشی تکنیکهای خاص ماهیگیری مرتبط کرده است؟ آیا تا به حال یک سایت ماهیگیری تمام انواع ماهیان را پوشش داده و انواع روشهای ماهیگیری، قلابها و طعمههای مناسب هر ماهی را به آن لینک کرده است؟ اینها نمونههایی از ایدههای موضوعی عمیق و منحصربفرد هستند که میتوان بررسی کرد.
بنابراین قابل درک است که چگونه گسترش موضوعات میتواند به بهبود و ارتقای محتوایی منحصربفرد و ارزشمند کمک کند. هنگام برنامهریزی تولید محتوا این نکات را در نظر داشته باشید. صرفاً مطالب و محتوای تکراری تولید نکنید. برای محتوای خود ارزش افزوده ایجاد کنید و منحصربفرد باشید. از الگوریتمهای مذکور در این مقاله به عنوان راهنمای خود استفاده کنید.


