










طبق آخرین پتنت گوگل این موتور جستجو با استفاده از محدودیتها (Constraint)، پاسخهای بهتر و دقیقتری برای جستجوها و درخواستهای کاربران (Query) تولید می کند. زیرا محدودیتها باعث میشوند دامنه پاسخها محدود شده و پاسخهای مرتبطتری تولید و ارائه شود.
استفاده از محدودیتها برای پاسخ به درخواستهای جستجو
این پتنت گوگل روشی هوشمندانه برای پاسخگویی دقیق به سوالات و درخواستهای جستجوی کاربران ارائه میدهد و نحوه پاسخدهی به درخواستهای کاربران با استفاده از مفاهیم و اصول سئو سایت معنایی و هوش مصنوعی را مشخص میکند. در این روش، زمانی که کاربر سؤالی مطرح میکند یا عبارتی را جستجو مینماید، سیستم با بررسی محتوای مرتبط با موضوع جستجو شده، سعی میکند پاسخ صحیح را با در نظر گرفتن محدودیتها و قوانین مشخص، استخراج و ارائه کند. به عنوان مثال، اگر درخواست جستجو یا سوال درباره یک مکان یا شخص خاص باشد، سیستم با جستجو در مخزن دانش خود و یافتن اطلاعات مربوط به آن موجودیت، سعی میکند پاسخ را استخراج کند.
سپس با اعمال محدودیتهایی مانند زمان و مکان، صحت اطلاعات و ربط آنها به عبارت جستجو شده، پاسخها را فیلتر و دقیقتر میکند. همچنین این سیستم میتواند از تکنیکهای جستجوی معنایی و گراف دانش برای یافتن ارتباطات میان مفاهیم و موجودیتها، و ارائه بهترین پاسخ استفاده کند. آگاهی از این فرایند برای هر کسی که قصد سئو یک سایت را دارد خصوصا ارائه دهندگان خدمات سئو بسیار مهم است.
پاسخ به درخواست جستجو از طریق داده های استخراج شده از یک پایگاه داده
سیستمهای جستجوی اطلاعات اغلب از طریق دسترسی به پایگاههای داده و استخراج اطلاعات از آنها، به سؤالات عینی کاربران پاسخ میدهند. این حقایق در یک گراف داده ذخیره میشوند که به صورت آنلاین بهروزرسانی میشود. پاسخهای حاصل از این سیستمها معمولاً نه به صورت جملات کامل و منسجم، بلکه به صورت لیستی از نتایج جستجو ارائه میگردد.
به عنوان مثال زمانیکه کاربران از طریق سیستمهای گفتگوی صوتی سؤالات عینی مطرح میکنند، ارائه پاسخی طبیعی و روانتر با ادبیات معمول بسیار مطلوب است. طبیعیترین پاسخ، جملهای دستوری و منسجم از حقایق مرتبط با سؤال کاربر است که بتواند نیاز اطلاعاتی او را برآورده سازد. به همین منظور، در پاسخگویی به سؤالات عینی، داده های ذخیرهشده در پایگاهدادهها به جملاتی در زبان طبیعی کاربر تبدیل میشوند تا پاسخها برای کاربران قابلفهمتر و کاربردیتر باشد.
دریافت پاسخهای حاوی ویژگیها و مشخصات یک موجودیت یا Entity
یکی از جنبههای موضوع توصیف شده در این پتنت، روش پاسخدهی به سؤالاتی است که درباره ویژگیها و خصوصیات یک موجودیت یا Entity، شیء یا مفهوم خاص پرسیده میشوند. زمانی که چنین سؤالی دریافت میشود، سیستم ابتدا الگوهای مختلف پاسخ را بر اساس آن شیء یا موجودیت بازیابی میکند. این الگوها حاوی فیلدهایی هستند که هر کدام محدودیتهایی دارند.
سپس سیستم با جستجو در منابع اطلاعاتی خود، دادهها و حقایق مربوط به آن شیء یا موجودیت را به دست میآورد. در نهایت الگویی انتخاب میشود که بیشترین تطابق را با دادههای بهدستآمده داشته باشد. سپس با قرار دادن دادهها در فیلدهای مناسب، پاسخی منسجم، مرتبط و دقیق برای سؤال کاربر تولید میشود. این روش باعث میشود پاسخها، متناسب با سؤال و حاوی اطلاعات مفید باشند.
سهگانه معنایی مرتبط با موجودیتها
سیستمهای هوشمند پاسخگو به سؤالات کاربران، برای تولید پاسخهایی طبیعی و قابل فهم، از مجموعهای متشکل از سهگانه موجودیت-ویژگی-مقدار بهره میبرند. این سهگانه حاوی اطلاعات مورد نیاز برای پاسخگویی به سوالات کاربران است. سپس الگوهایی برای ساخت جمله انتخاب میشود و مجموعه اطلاعات به فیلدهای این الگوها اضافه میگردد تا عبارت یا جملهای تولید شود که حاوی پاسخ سؤال کاربر است. این عبارت میتواند یک جمله کامل یا بخشی از یک جمله باشد. در نهایت عبارت تولیدشده حاوی پاسخ، ممکن است به عنوان یک عبارت صوتی مربتط با کلمات سرچ شده ارسال شود. این روش باعث میشود پاسخهای ارائه شده، دقیق، مرتبط و در قالبی طبیعی و قابل فهم برای کاربر باشد و تعامل کاربر و سیستم را بهبود میبخشد.
در تولید جملات طبیعی توسط سیستمهای هوشمند، محدودیتهایی اعمال میشود تا جملات تولیدی دقیق و مناسب باشند. این محدودیتها شامل موارد زیر است:
- محدودیت نوع (مثلا اسم، فعل و غیره)
- محدودیت زمانی
- محدودیت جنسیت
- محدودیت رابطهای
- محدودیت مفرد/جمع
- محدودیت واحد اندازهگیری
- محدودیت تعیینکنندهها (مثل حروف تعریف)
در اقدامات مرتبط با پاسخ به یک ویژگی از عبارت جستجو شده توسط کاربر، چندین مجموعه اطلاعات استخراج میشود و اقدامات اغلب شامل موارد زیر است:
- انتخاب الگوی جمله بر اساس نوع موجودیت مورد نظر
- افزودن عبارات به فیلدهای قالب جمله برای تشکیل جمله
- انتخاب الگویی از میان الگوهای مشخص برای هر مجموعه از اطلاعات
- ایجاد یک عبارت برای هر الگوی انتخابی با افزودن مجموعه اطلاعات مربوطه به فیلدهای الگوی انتخابی مربوطه
- ارسال جمله حاوی این عبارتها برای کاربر
تولید پاسخ جامع به درخواستهای جستجو شامل پاسخ به سؤالاتی است که حاوی ویژگیهای متعددی هستند:
- دریافت پاسخهایی که ویژگیهای متعدد یک موجودیت را شناسایی و مشخص میکنند
- برای هر ویژگی از موجودیت، دسترسی به مجموعهای از الگوهای منتخب برای پاسخهای درخواست جستجو بر اساس ویژگی مربوطه از موجودیت
- به دست آوردن مجموعهای از اطلاعات برای هر ویژگی از موجودیت که بخش مربوطی از سؤال را پاسخ میدهد
- انتخاب الگویی از مجموعه مربوطه از الگوهای مشخص
- ایجاد عبارت برای هر ویژگی از موجودیت، با افزودن مجموعه اطلاعات مربوط به فیلدهای الگوی انتخاب شده
- به دست آوردن الگوی جملهای بر اساس نوع موجودیت که در آن الگوی جمله شامل چندین فیلد برای عبارتها است
- افزودن عبارات به فیلدهای الگوی جمله برای تشکیل یک جمله
- ارسال جمله حاوی عبارتها به دستگاه یا پلتفرم کاربر
مزایای این فرآیند شامل موارد زیر است:
- سیستم قابل پیکربندی و گسترش به اظهارات و پاسخهای پیچیده مبتنی بر واقعیت است.
- امکان جداسازی کامل پایگاه داده واقعی از مکانیزم تولید جمله را فراهم میکند.
- افزودن الگوهای جدید را از طریق هر روش مناسبی امکانپذیر میسازد.
خلاصه فرآیند تولید پاسخ به درخواستهای کاربران در پتنت
- یک سرور پاسخهای درخواست جستجو شده را دریافت میکند که ویژگیهای یک موجودیت را مشخص میکند.
- سرور به مجموعهای از الگوهای کاندید برای پاسخ به درخواست بر اساس ویژگیهای موجودیت دسترسی پیدا میکند که هر الگو دارای فیلدهایی است که هر فیلد با حداقل یک محدودیت مرتبط است.
- سرور مجموعهای از اطلاعات و پاسخهای درخواست جستجو را به دست میآورد و الگویی را از مجموعه الگوهای کاندید انتخاب میکند.
- الگوی انتخاب شده دارای بیشترین تعداد فیلد با محدودیت های برآورده شده توسط مجموعه اطلاعات است.
- سرور با افزودن مجموعهای از اطلاعات به فیلدهای الگوی انتخابی، عبارت را تولید میکند، به گونهای که عبارت شامل پاسخی به درخواست باشد.
- در نهایت، سرور عبارت را به دستگاه کاربر ارسال میکند.
تبدیل داده های استخراج شده از پایگاه داده به جمله یا عبارت
هنگامی که کاربران سؤالات عینی مطرح میکنند، موتورهای جستجو اغلب با دسترسی به پایگاهدادهها، پاسخ سؤال را استخراج و ارائه میدهند. در سیستمهای گفتگو محور مبتنی بر زبان طبیعی (Natural Language) مانند سیستمهای گفتگوی صوتی، امکان طرح سؤال به صورت جملات عادی برای کاربر فراهم شده است. در این حالتها، ارائه پاسخ به شکل یک جمله طبیعی و قابل فهم بسیار مطلوب تر است، نسبت به نمایش نتایج جستجوی که کاربر را به منابع و سایت ها ارجاع می دهد، و برای کاربران قابل درک است.
این سیستمها میتوانند حقایق موجود در پایگاهداده را به جملات تبدیل کنند. این ویژگی به ارائه پاسخها به شکل گفتاری برای کاربر کمک میکند. برای تولید جملات حاوی پاسخ سؤال کاربر، استخراج حقایق مرتبط از پایگاهداده ضروری است. این داده ها با استفاده از اطلاعات محدودیتها، پاسخ سؤال را فراهم میکنند و منجر به پاسخگویی بهتر به سؤالات مربوط به موجودیتها میشود. به عنوان مثال برای پاسخ به سؤال درباره همسر یک فرد، سیستم اطلاعاتی شامل ازدواجهای گذشته، افراد درگیر، تاریخ و نوع توافقنامه ازدواج را بازیابی میکند. یک پایگاه داده انعطافپذیر که از ساختار گراف داده استفاده میکند، میتواند این حقایق را ارائه دهد.
دسترسی به الگوهای احتمالی برای تولید پاسخ به درخواست جستجو بر اساس ویژگی/ویژگیها
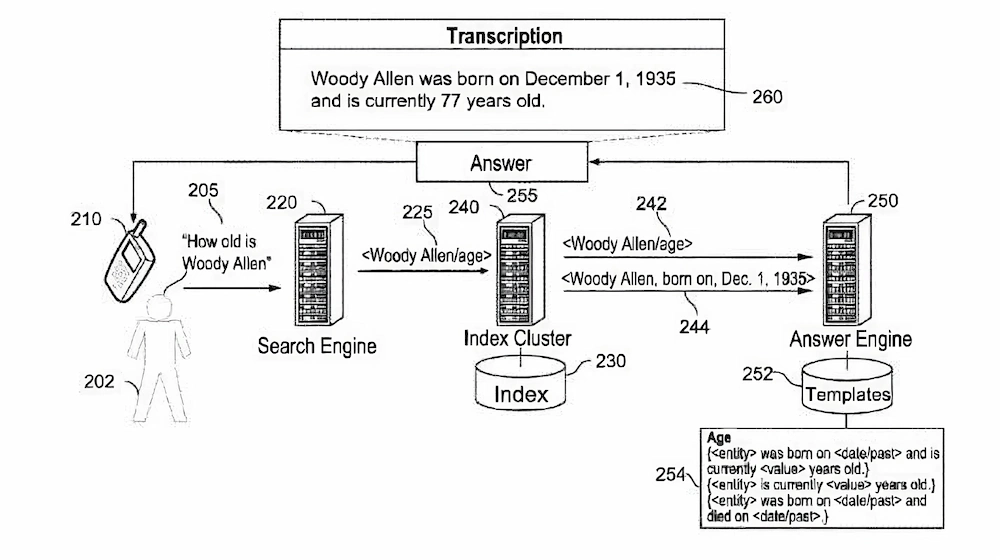
پس از جمعآوری حقایق مرتبط با سؤال کاربر، موتور پاسخگویی الگوهای مناسبی را بر اساس ویژگی یا ویژگیهای مشخص شده در سؤال، برای تولید پاسخ انتخاب میکند. به عنوان مثال اگر سؤال درباره همسر یک شخص (مثلاً وودی آلن) باشد، الگوهای مرتبط با ویژگی “ازدواج” و اگر سؤال درباره سن شخص باشد، الگوهای مرتبط با ویژگی “سن” مد نظر قرار میگیرد. همچنین برای هر ویژگی میتوان چند الگوی مختلف در نظر گرفت تا پاسخهایی با جزئیات بیشتر یا کمتر تولید شود.
به عنوان مثال برای ویژگی سن میتوان الگوهایی شامل تاریخ تولد و سن، فقط سن یا تاریخ تولد و تاریخ فوت را به ترتیب زیر بکار برد. قسمتهای الگو که درون علامت «<>» قرار گرفتهاند (یعنی فیلدها)، ممکن است دارای محدودیتهایی در مورد نوع دادهای باشند که میتوانند در خود نگه دارند.
{entity> was born on <date> and Is currently <value> years old>}
{entity> is currently <value> years old>}
{<entity> was born on <date> and died on </date>}
زمانی که موتور پاسخگو الگوهای احتمالی را بازیابی کرد، بر اساس چندین قاعده اکتشافی، مرتبطترین الگو را انتخاب نموده و با قرار دادن داده ها در فیلدهای آن الگو، جملهای حاوی پاسخ تولید میکند. سپس این پاسخ به شکلی صحیح و دقیق برای کاربر ارسال میشود.
سیستم جستجوی مبتنی بر گراف داده
این سیستم از تکنیکهای خاصی برای جستجو در گرافهای داده پیچیده استفاده میکند. سیستم درخواستهای جستجو را دریافت میکند و پاسخ مناسب را برمبنای دادههای موجود در گراف ارائه میدهد. این سیستم میتواند شامل بخشهای مختلفی مانند سیستم فهرستبندی، سیستم جستجو و خوشه فهرست باشد که به صورت توزیع شده بر روی سرورهای مختلف اجرا میشوند. هدف اصلی این سیستم فراهم کردن امکان جستجوی سریع و کارآمد در گرافهای داده بزرگ و پیچیده است.
سیستم جستجوی گراف دادهها را میتوان بر روی یک رایانه شخصی یا لپتاپ پیادهسازی کرد. در این سیستم، دادهها به صورت یک گراف ذخیره میشوند که شامل گرهها و یالهاست. گرهها نشاندهنده موجودیتها (انتیتی ها) و یالها نشاندهنده روابط بین آنها هستند. این روابط و موجودیتها به صورت سهتایی ذخیره میشوند تا بتوان از روی آنها گرافی از دادهها ایجاد کرد. با استفاده از این روش میتوان جستجو در گرافهای داده بزرگ را بر روی یک رایانه شخصی پیادهسازی نمود.
مجموعه های سهگانه نشان دهنده موجودیتها و روابط آنها
در نمایش دادهها و اطلاعات به صورت گراف، از ساختار سهتایی برای نشان دادن روابط بین موجودیتها استفاده میشود. در این روش هر ساختار سهگانه متشکل از یک موجودیت، خصیصهای که با موجودیت دیگر مرتبط است و مقدار آن خصیصه در موجودیت مرتبط است. با استفاده از میلیونها ساختار سهتایی میتوان گراف بزرگی از ارتباطات بین موجودیتها ایجاد کرد. برای جستجو در این گرافها نیز از سیستمهای فهرستبندی ویژهای استفاده میشود.
به عنوان مثال، یک نمونه از ساختار سهتایی، موجودیت وودی آلن به عنوان موضوع (یا موجودیت)، رابطه “بازی کردن در” به عنوان فعل (یا ویژگی)، و موجودیت فیلم Annie Hall به عنوان مفعول (یا مقدار) است.
یافتن پاسخ درخواستهای جستجو در سیستم گراف داده
سیستمهای جستجو میتوانند از این گرافهای دادهای و الگوریتمهای پردازشی برای پاسخگویی به درخواستهای جستجوی کاربران استفاده کنند. در این سیستمها، درخواستهای جستجو پس از دریافت، پردازش و سپس بر روی گرافهای دادهای و سایر منابع اطلاعاتی جستجو میشوند تا نتایج مرتبط پیدا شود. استفاده از گرافهای دادهای به سیستمهای جستجو این امکان را میدهد تا به طور مؤثری ارتباطات بین دادهها را مدلسازی و جستجو کنند.
سیستم جستجو ممکن است شامل سرورهایی باشد که درخواستهای جستجو را از کاربران دریافت کرده و بر روی گراف داده و منابع دیگر جستجو انجام میدهند. به عنوان مثال، سیستم جستجو ممکن است درخواستی را دریافت کرده و پس از پردازش، آن را برای خوشههای ایندکس (Index Cluster) مختلف ارسال کند تا روی منابع مختلف جستجو شود.
سیستمهای جستجو میتوانند شامل ماژولهایی برای جمعآوری و یکپارچهسازی نتایج جستجو از منابع اطلاعاتی متفاوت باشند. این سیستمها از طریق شبکه با کاربران ارتباط برقرار میکنند و درخواستهای جستجوی آنها را دریافت مینمایند. سپس با ارسال این درخواستها به خوشههای ایندکس منابع اطلاعاتی و دریافت نتایج، آنها را پردازش و یکپارچه کرده و نتایج نهایی را برای کاربر ارسال میکنند.
نقش خوشههای ایندکس در یافتن پاسخ درخواستهای جستجو
این سیستم میتواند شامل یک خوشه ایندکس یا فهرستبندی باشد. کلاستر ایندکس میتواند یک دستگاه محاسباتی واحد یا یک سیستم پایگاه داده توزیع شده با چندین دستگاه با پردازنده و حافظه مجزا باشد. تعداد دستگاههای محاسباتی تشکیل دهنده خوشه ایندکس میتواند متغیر باشد و برای اختصار، کلاستر فهرستبندی به عنوان یک موجودیت واحد نشان داده میشود. هر خوشه ایندکس میتواند شامل پردازندههایی باشد که برای اجرای دستورالعملها یا نرمافزارها و سختافزارها یا ترکیبی از آنها پیکربندی شده باشد.
خوشههای محاسباتی معمولاً شامل سیستمعامل و انواع مختلف حافظههای رایانهای مانند حافظه اصلی و حافظههای جانبی میشوند که میتوانند برای ذخیرهسازی دادهها به صورت موقتی، دائمی، نیمهدائمی یا ترکیبی از آنها پیکربندی شده و مورد استفاده قرار گیرند. حافظه میتواند هر نوع دستگاه ذخیرهسازی باشد که اطلاعات را به فرمتهای قابل پردازش و قابل اجرا توسط پردازندهها ذخیره میکند. حافظههای فرار برای ذخیرهسازی موقت دادهها و حافظههای غیرفرار برای ذخیرهسازی دائمی دادهها بکار میروند.
ماژول حل کننده درخواست که با دسترسی به ایندکس نتایج مربوط به درخواست را بدست می آورد
خوشههای ایندکس معمولاً شامل ماژولهای حلکننده درخواست هستند که مسئولیت دسترسی به فهرست و بازیابی نتایج مرتبط با درخواستهای جستجو را برعهده دارند. این ماژولها پس از دریافت درخواست جستجو از سیستم جستجو، با مراجعه به فهرست و جستجو در آن، نتایج مرتبط را استخراج و بازگردانی میکنند. ماژولهای حلکننده درخواست میتوانند بخشی از خود سیستم جستجو باشند یا به صورت توزیع شدهای در خوشه فهرستبندی و سیستم جستجو مستقر شوند تا کارایی سیستم را افزایش دهند.
کوئری ها و پاسخ های پیچیده تر
سیستمهای جستجو میتوانند درخواستهای جستجو با سطوح مختلف پیچیدگی دریافت کنند. درخواستهای ساده ممکن است فقط شامل یک ویژگی (مانند سن) باشند که منجر به یک پاسخ سهتایی میشود. در حالی که درخواستهای پیچیده میتوانند شامل چندین ویژگی (مثلاً زادگاه و محل تحصیل) باشند که منجر به چند پاسخ سهتایی میشود. سیستمهای پیشرفته میتوانند علاوه بر بازگرداندن پاسخهای ساده، در قالب جملاتی معنادار به درخواستها پاسخ دهند. این سیستمها معمولاً شامل اجزایی همچون دستگاه مورد استفاده کاربر، سیستم جستجو، خوشه فهرستبندی و موتور پاسخدهی هستند که با همکاری یکدیگر میتوانند به درخواستهای پیچیده کاربران پاسخ دهند.
تعامل با یک سیستم گفتگوی مبتنی بر صدا
سیستمهای جستجوی پیشرفته امکان تعامل کاربر به صورت گفتاری را فراهم میکنند. کاربر میتواند درخواست خود را به صورت گفتار وارد کند که توسط دستگاه مشتری ضبط و پس از تبدیل به متن، برای سیستم جستجو ارسال میشود. سیستم جستجو نیز با استفاده از موتورهای تجزیه زبان طبیعی، درخواست را تجزیه و سازماندهی کرده و سپس بخش مرتبط را به کلاستر فهرستبندی برای دسترسی به اطلاعات و بازیابی نتایج ارسال میکند. در نهایت نتایج بازیابی شده برای کاربر ارائه میشود.
به عنوان مثال، کاربر ممکن است درخواست “سن وودی آلن چقدر است؟” را به میکروفن دستگاه خود بگوید. دستگاه با استفاده از تشخیص گفتار، گفتار را به متن تبدیل کرده و آن را برای موتور جستجو ارسال میکند. یا به جای آن، دادههای صوتی گفتار را ارسال میکند. سیستم جستجو درخواست (مثلا “سن وودی آلن چقدر است؟”) را از دستگاه کاربر دریافت میکند. اگر درخواست به صورت داده صوتی باشد، آن را به متن تبدیل میکند. سپس سیستم جستجو درخواست اصلی را با استفاده از موتور تجزیه زبان طبیعی مناسب، تجزیه و فرمتبندی میکند و آن را به کلاستر فهرستبندی ارسال میکند که کلاستر با دسترسی به فهرست، نتایج مرتبط با درخواست را بازیابی میکند.
پاسخ درخواستهای جستجو به صورت الگوی سهتایی
این نتایج ممکن است مجموعهای از اطلاعات واقعی در قالب یک الگوی سهتایی باشد (مانند: </woody><woody Allen/born/Dec.1,>)، سپس خوشه ایندکس، درخواست جستجوی فرمتبندی شده ( مانند: </woody><woody Allen/age>) و اطلاعات واقعی که به درخواست پاسخ میدهد ( مانند: </woody><woody Allen/born/’ec. 1, 1935>) را به موتور جستجو ارسال میکند. موتور جستجو با استفاده از درخواست فرمتبندی شده و اطلاعات واقعی، پاسخی را در قالب یک جمله یا عبارات تولید و ارائه میکند.
موتور جستجو پاسخ را به این صورت تولید میکند:
ابتدا، ویژگی یا ویژگیها را از درخواست جستجوی فرمتبندی شده استخراج میکند.
سپس، از ویژگی یا ویژگیها برای دسترسی به قالبهای جمله یا عبارت موجود از پایگاه داده الگو استفاده میکند.
در مرحله بعد، موتور جستجو یکی از الگوها را بر اساس اطلاعات واقعی و محدودیتهای مختلف مرتبط با الگوهای موجود انتخاب میکند.
در نهایت، موتور جستجو، فیلدهای قالب انتخاب شده را با استفاده از اطلاعات واقعی پر میکند.
استخراج ویژگی/ویژگیها توسط موتور جستجو
موتور پاسخدهی سیستمهای جستجو، وظیفه تولید پاسخهای مناسب به درخواستهای کاربران را برعهده دارد. این موتورها ابتدا ویژگیهای مورد درخواست را از درخواست ورودی استخراج میکنند. سپس با مراجعه به پایگاه الگوها، الگوهای مناسب برای تولید پاسخ را بر اساس ویژگیهای استخراج شده، بازیابی مینمایند. این الگوها حاوی فیلدهایی برای قرارگیری اطلاعات واقعی هستند. در نهایت موتور پاسخدهی با قرار دادن اطلاعات در فیلدهای الگو و تولید جمله، پاسخ نهایی را برای کاربر تولید میکند.
به عنوان مثال، فرض کنید درخواست به صورت یک جفت <موجودیت/ویژگی> فرمتبندی شده باشد، موتور پاسخدهی بخش ویژگی جفت را استخراج میکند. یا در برخی موارد، درخواست فرمتبندی شده ممکن است چندین ویژگی داشته باشد. به عنوان مثال، درخواست فرمتبندی شده ممکن است به صورت <موجودیت/ویژگی/ویژگی> باشد. در چنین مواردی، موتور پاسخدهی هر ویژگی را از درخواست استخراج میکند. سپس، موتور پاسخدهی الگوهای موجود برای هر ویژگی در درخواست را از پایگاه داده الگو انتخاب میکند. هر الگو ممکن است متناظر با یک جمله کامل یا بخشی از جمله (مثلاً عبارت) باشد. هر الگو شامل فیلدهایی (نشان داده شده به عنوان بخشها در<> میباشد) است که اطلاعات حقیقی میتوانند در آنها جایگزین شوند. مثلاً یک الگو ممکن است “در <تاریخ>، <موجودیت> با <مقدار> ازدواج کرد” باشد. الگوها میتوانند به صورت دستی یا الگوریتمی تولید شوند.
الگوهای منتخب به زبان کاربر
موتور پاسخدهی با تشخیص زبان کاربر، الگوهایی را در همان زبان برای تولید پاسخ انتخاب میکند تا قابل فهم بودن پاسخ برای کاربر تضمین شود. همچنین بر روی فیلدهای الگوها میتوان انواع مختلف محدودیتها را اعمال کرد تا نوع دادهای که در آن قرار میگیرد کنترل شود. این محدودیتها شامل محدودیتهایی مانند نوع داده، زمان، جنسیت، رابطه، تعداد و واحد اندازهگیری هستند که با اعمال آنها میتوان تولید پاسخهای دقیق و منطقی را تسهیل کرد.
محدودیتهای مختلف ممکن است مستلزم دادههای مختلف باشند
محدودیت نوع ممکن است نیاز به نوع خاصی از داده داشته باشد. به عنوان مثال، محدودیت <تاریخ> ممکن است یک تاریخ، محدودیت <موجودیت> ممکن است نام یا شناسه موجودیت و محدودیت <عدد> ممکن است یک عدد را نیاز داشته باشد.
محدودیت زمانی ممکن است نیاز داشته باشد که تاریخ یا زمان در گذشته یا آینده باشد. به عنوان مثال، فیلد حاوی <تاریخ/گذشته> ممکن است نیاز داشته باشد که فیلد شامل تاریخی در گذشته باشد. محدودیت جنسیتی ممکن است نیاز به جنسیت مذکر یا مونث داشته باشد. محدودیت رابطهای ممکن است نوع خاصی از رابطه با موجودیت دیگر را نیاز داشته باشد. به عنوان مثال، فیلد حاوی <موجودیت/همسر> ممکن است نیاز داشته باشد که فیلد شامل موجودیتی باشد که همسر موجودیت دیگر است.
محدودیت مفرد/جمع ممکن است نیاز داشته باشد داده در فیلد به صورت مفرد یا جمع باشد. محدودیت واحد اندازهگیری ممکن است نیاز داشته باشد داده در فیلد با واحد اندازهگیری خاصی سنجیده شود. محدودیت تعیینکننده ممکن است نیاز داشته باشد کلمه “the” قبل از فیلد قرار گیرد.
هر ویژگی در درخواست جستجو میتواند به عنوان کلیدی برای دسترسی به مجموعهای از الگوهای منتخب عمل کند. به عنوان مثال، ویژگی “سن” ممکن است منجر به بازیابی الگوهای زیر شود:
الگوی اول ” در تاریخ <تاریخ/گذشته> متولد شد و در حال حاضر <مقدار> سال دارد”، به نام موجودیت برای فیلد <موجودیت>، تاریخی در گذشته برای فیلد <تاریخ/گذشته> و یک عدد (مثلاً سن) برای فیلد <مقدار> نیاز دارد.
الگوی دوم “<موجودیت> در حال حاضر <مقدار> سال دارد” نیاز به نام موجودیت برای فیلد <موجودیت> و یک عدد (مثلاً سن) برای فیلد <مقدار> دارد.
الگوی سوم “<موجودیت> در تاریخ <تاریخ/گذشته> متولد و در تاریخ <تاریخ/گذشته> درگذشت” نیاز به نام موجودیت برای فیلد </موجودیت><موجودیت> و دو تاریخ گذشته برای فیلدهای <تاریخ/گذشته> دارد.
الگوهای متعدد برای ویژگیهای داده شده
داشتن چندین الگو برای هر ویژگی، به سیستم پاسخدهی امکان میدهد در صورت وجود اطلاعات ناقص، الگوی مناسب را انتخاب کند. به عنوان مثال، برای الگوهای سنی، اگر سال تولد مشخص باشد اما تاریخ دقیق نامشخص باشد، الگوی مناسب میتواند به صورت “<موجودیت> در سال <سال/گذشته> متولد شد” باشد. موتور پاسخدهی با در نظر گرفتن عواملی مانند تطابق جنسیتی، زمان صحیح و تعداد پاسخها، الگوی مناسب را از میان الگوهای منتخب انتخاب میکند تا بتواند پاسخ دقیق و طبیعی بر اساس حقایق موجود تولید کند. همچنین ممکن است تعداد پاسخهای درخواست اصلی را با تعداد فیلدهای الگوی انتخاب شده مقایسه کند.
موتور پاسخدهی با بررسی الگوهای منتخب از نظر برآورده شدن محدودیتهای فیلدها توسط دادههای واقعی، الگویی را انتخاب میکند که بیشترین تطابق را داشته باشد و حاوی بیشترین داده باشد ( مثلاً «<وودی آلن/در اول دسامبر، 1935/متولد شده است>.”). هر چه الگو تعداد بیشتری فیلد با محدودیتهای برآورده شده داشته باشد، مناسبتر است. این رویکرد باعث میشود پاسخها حداکثر اطلاعات ممکن را بر اساس دادههای موجود داشته باشند.
در مثال پیشنهادی، الگوی منتخب اول “<موجودیت> در تاریخ <تاریخ/گذشته> متولد شده و در حال حاضر سال دارد” است. این الگو شامل فیلد <موجودیت>، <تاریخ/گذشته> و <مقدار> است که اطلاعات حقیقی یک موجودیت را فراهم میکند که محدودیت فیلد <موجودیت> و یک تاریخ گذشته را که محدودیت فیلد <تاریخ/گذشته> را برآورده میکند.
موتور پاسخدهی با استفاده از اطلاعات حقیقی، مقادیر لازم برای پر کردن فیلدهای الگو را محاسبه و استخراج میکند. الگویی که بیشترین تطابق را با اطلاعات داشته باشد و فیلدهای بیشتری از آن با اطلاعات موجود تکمیل گردد، به عنوان الگوی منتخب انتخاب میشود. این رویکرد ارائه پاسخهای حاوی بیشترین اطلاعات ممکن بر اساس دادههای در دسترس را تضمین میکند.
موتور پاسخدهی پس از انتخاب الگوی مناسب، با جایگزین کردن دادههای واقعی در فیلدهای الگو، جمله را متناسب با الگو تولید میکند. سپس پاسخی شامل جمله تولید شده به صورت متنی یا صوتی برای کاربر ارسال میشود. به عنوان مثال، موتور پاسخدهی میتواند فیلدهای الگو را با دادههای مناسب از اطلاعات حقیقی جایگزین کند. موتور پاسخدهی با استفاده از الگوی انتخاب شده، جمله “وودی آلن در تاریخ 1 دسامبر 1935 متولد شده و در حال حاضر 77 سال دارد” را تولید میکند.
سیستم تولید جملات در پاسخ به درخواستهای مبتنی بر دادههای واقعی
سیستمهای پاسخگو شامل اجزایی مانند دستگاه کاربر، سیستم جستجو و موتور پاسخدهی هستند که با همکاری یکدیگر، درخواست کاربر را دریافت کرده، آن را با استفاده از تکنیکهای پردازش زبان طبیعی تجزیه و سازماندهی میکنند و اطلاعات لازم را استخراج نموده و بخش مرتبط را برای جستجو و بازیابی پاسخ به بخش فهرستبندی ارسال مینمایند.
در این فرآیند دستگاه کاربر یک درخواست شامل عبارات درخواست جستجو را آغاز میکند. به عنوان مثال، کاربر در درخواست جستجوی خود، عبارت “وودی آلن با چه کسی ازدواج کرده است؟” را وارد میکند. سیستم جستجو درخواست را دریافت کرده و با استفاده از موتور تجزیه زبان طبیعی آن را تجزیه و فرمتبندی میکند. در این مثال، درخواست فرمتبندی شده شامل شناسه موجودیت، نوع موجودیت و ویژگی است که اطلاعات نوع موجودیت برای تولید الگوی فرادادهای استفاده میشود. سپس سیستم جستجو درخواست فرمتبندی شده را به کلاستر فهرستبندی ارسال میکند.
خوشه ایندکس به فهرست دسترسی پیدا میکند تا مجموعهای از اطلاعات حقیقی مرتبط با درخواست را بازیابی کند
خوشه ایندکس یا کلاستر فهرستبندی با دسترسی به فهرست، دادهها و اطلاعات مورد نیاز برای پاسخ به درخواست را بازیابی کرده و برای موتور پاسخدهی ارسال میکند. موتور پاسخدهی نیز با توجه به نوع موجودیت، الگوهای متناسب را انتخاب نموده و با قراردادن اطلاعات در الگوها، پاسخ نهایی را به صورت یک یا چند جمله تولید مینماید.
در این فرآیند، کلاستر فهرستبندی با دسترسی به فهرست، مجموعهای از اطلاعات حقیقی مرتبط با درخواست را بازیابی میکند. این نتایج شامل حداقل دو سهتایی هستند (به عنوان مثال <لوئیز لسر/ همسر/ ۱۹۶۶-۱۹۷۰ >). سپس کلاستر فهرستبندی درخواست فرمتبندی شده و اطلاعات حقیقی که پاسخ درخواست هستند را به موتور پاسخدهی ارسال میکند. موتور پاسخدهی با استفاده از درخواست فرمتبندی شده و اطلاعات حقیقی، پاسخ را در قالب یک یا چند جمله به شرح زیر تولید میکند:
ابتدا اطلاعات نوع را از درخواست استخراج میکند. این اطلاعات نوع موجودیت مورد درخواست را مشخص میکند.
سپس با استفاده از اطلاعات نوع موجودیت، دسترسی به الگوهای فرادادهای مرتبط با نوع “شخص” را فراهم میکند. الگوهای فرادادهای الگوهایی هستند که فیلدهایی برای گنجاندن سایر الگوها دارند.
قالبهای متا یا الگوهای فرادادهای حاوی فیلدهایی برای نام یا شناسه یک موجودیت مانند یک شخص و همچنین فیلدهایی برای اضافه کردن سایر الگوها هستند. با استفاده از این الگوها، موتور پاسخگو میتواند جملاتی حاوی اطلاعات مختلف درباره یک شخص تولید کند. همچنین برخی از قالبهای عبارت برای ادغام در قالبهای متا طراحی شدهاند و اطلاعات مفصلتری را فراهم میکنند.
موتور پاسخگو از قالبهای مختلف عبارت برای تولید پاسخ به پرسشهای مرتبط با ویژگی “ازدواج” استفاده میکند. زمانی که درخواستی حاوی ویژگی “ازدواج/ زوجها” دریافت میشود، موتور پاسخگو به مجموعهای از قالبهای عبارت مرتبط دسترسی پیدا میکند. این قالبهای عبارت الگوهایی برای تولید جملات در مورد وضعیت ازدواج یک شخص هستند.
به عنوان مثال، قالب “از <تاریخ/گذشته> با <موجودیت/همسر> ازدواج کرده است”، نیاز به اطلاعاتی در مورد شخصی که فرد مورد نظر با او ازدواج کرده و تاریخ ازدواج دارد. قالب “متأهل است” نیاز به اطلاعات اضافی ندارد. با ترکیب این قالبها و قرار دادن اطلاعات در فیلدهای مناسب، موتور پاسخگو میتواند به طور خودکار پاسخهایی در مورد وضعیت ازدواج یک شخص تولید کند. این روند امکان تولید پاسخهای غنی، دقیق و مناسب به انواع پرسشها در مورد ازدواج افراد را برای موتور پاسخگو فراهم میکند.
در مرحله بعد، موتور پاسخگوی هوشمند ابتدا چند متا الگوی کاندید برای پاسخ به سؤال را بر اساس نوع اطلاعات واقعی موجود انتخاب میکند. سپس با توجه به تعداد سهتاییهای اطلاعاتی موجود در سؤال، یکی از الگوهای متا را که تعداد فیلدهای مناسب دارد، انتخاب میکند. به عنوان مثال برای هر سهگانه موجود در سؤال، الگوی “شخص” که دو فیلد برای دو قالب دارد، انتخاب میشود. سپس برای هر سهگانه موجود در اطلاعات واقعی، موتور پاسخگو یک قالب از میان قالبهای مناسب انتخاب میکند. قالبی که بیشترین تناسب را با اطلاعات سؤال داشته باشد و بتواند بیشترین اطلاعات را در خود جای دهد، انتخاب میشود. با پر کردن الگوی متا و قالبهای انتخاب شده با اطلاعات واقعی، موتور پاسخگو میتواند پاسخی مناسب و غنی به سؤال ارائه کند.
اولین سهتایی موجود در اطلاعات واقعی <سون-یی پرهوین/همسر/۱۹۹۷> است. در این مثال، اولین الگوی عبارت کاندید «از سال ازدواج کرده است.» این الگو دارای یک فیلد <موجودیت/همسر> و یک فیلد <تاریخ/گذشته> است. سهتایی اول دارای یک موجودیت با رابطه همسر با موجودیت در درخواست قالببندی شده است که محدودیت فیلد <موجودیت/همسر> را برآورده میکند، و دارای تاریخی در گذشته است که محدودیتهای فیلد <تاریخ/گذشته> را برآورده می کند. از آنجایی که سهتایی اول تمام محدودیتهای فیلدهای اولین الگو را برآورده میکند، موتور پاسخگو اولین الگو را برای سهتایی اول انتخاب میکند.
سهتایی دوم موجود در اطلاعات واقعی شامل <لوئیز لسر/همسر/۱۹۶۶-۱۹۷۰> میباشد. چهارمین قالب منتخب عبارت “از <تاریخ/گذشته> تا <تاریخ/گذشته> ” ازدواج کرده است <موجودیت/همسر> است که شامل یک فیلد <موجودیت/همسر> و دو فیلد <تاریخ/گذشته> میباشد. این سهتایی یک موجودیت با رابطه همسر و دو تاریخ گذشته دارد که محدودیتهای سه فیلد قالب را برآورده میکند. بنابراین این قالب برای سهتایی دوم انتخاب میشود.
پس از انتخاب الگو و قالبهای مناسب، موتور جستجوی هوشمند فیلدهای قالبها را با اطلاعات واقعی جایگزین میکند تا جملهای معنادار و غنی به عنوان پاسخ سؤال تولید کند. این جمله به همراه سایر نتایج مرتبط با جستجوی کاربر در یک صفحه نمایش داده میشود تا کاربر بتواند پاسخ مناسب را مشاهده کند. موتور جستجو فیلدهای قالب اول را با اطلاعات سهتایی اول جایگزین میکند تا عبارت “از سال ۱۹۹۷ با سون-یی پرهوین ازدواج کرده است” تولید شود. سپس با قالب دوم، جمله کامل “وودی آلن از سال ۱۹۹۷ با سون-یی پرهوین ازدواج کرده است و قبلاً در سالهای ۱۹۹۶ تا ۱۹۷۰ لوئیز لسر همسر او بوده است” تولید میشود. این جمله به عنوان پاسخ به همراه سایر نتایج جستجو به دستگاه کاربر ارسال و نمایش داده میشود.
سیستم تولید جملات در پاسخ به درخواست های جستجوی واقعی
این سیستم شامل دستگاه کاربر، یک سیستم جستجو، یک خوشه فهرست و یک موتور پاسخدهی است. دستگاه کاربر یک درخواست جستجو حاوی دو اصطلاح جستجو (“زادگاه و دانشگاه محل تحصیل وودی آلن کجاست؟”) را در مرورگر وب دستگاه کاربر وارد میکند. سیستم جستجو درخواست جستجو را از دستگاه کاربر دریافت میکند. سپس سیستم جستجو درخواست اصلی را با استفاده از یک موتور مناسب پردازش زبان طبیعی تجزیه و به فرمت <موجودیت/نوع/ویژگی> (<وودی آلن/شخص/زادگاه/دانشگاه>) تبدیل میکند. در این مثال، درخواست فرمتبندی شده شامل شناسه موجودیت (وودی آلن)، نوع موجودیت (شخص) و دو ویژگی (زادگاه و دانشگاه) است. سپس سیستم جستجو درخواست فرمتبندی شده را به خوشه فهرست ارسال میکند.
موتور پاسخدهی هوشمند برای تولید پاسخ به صورت جمله یا جملات، ابتدا اطلاعات لازم از درخواست جستجوی فرمتبندی شده و دادههای واقعی را استخراج میکند. نوع موجودیت و ویژگیهای مورد نیاز جستجو از درخواست استخراج میشود. سپس الگوهای فرادادهای و قالبهای عبارت مرتبط با آنها از پایگاهداده بازیابی میشود. الگوها حاوی فیلد برای قرارگیری قالبهای عبارت هستند. در نهایت قالبهای عبارت در الگوی فرادادهای قرار گرفته و با اطلاعات واقعی پر میشوند تا پاسخ نهایی تولید شود.
هر ویژگی در درخواست جستجو میتواند به عنوان یک کلید برای دسترسی به مجموعهای از قالبهای عبارت منتخب عمل کند. به عنوان مثال، ویژگی “زادگاه” ممکن است منجر به بازیابی قالبهای عبارت شود. نمونه قالبهای عبارت شامل قالب اول “در حال حاضر در <مکان> زندگی میکند” است که نیاز به یک مکان جغرافیایی برای فیلد دارد. قالب دوم “از <تاریخ/گذشته> تاکنون در <مکان>/<مکان> زندگی کرده است” نیاز به یک مکان جغرافیایی برای فیلد <مکان>/<مکان> و یک تاریخ گذشته برای فیلد <تاریخ/گذشته> دارد. قالب سوم “قبلا در <مکان>/<مکان> زندگی میکرده است” نیاز به یک مکان جغرافیایی برای فیلد مکان دارد.
موتور پاسخدهی بر اساس نوع و مقدار اطلاعات واقعی موجود در درخواست جستجو، الگو و قالبهای عبارت مناسب را انتخاب میکند. ابتدا با توجه به تعداد سهتاییهای موجود در اطلاعات واقعی، الگوی مناسب انتخاب میشود. سپس برای هر سهتایی، قالبی که بیشترین تناسب را با اطلاعات دارد، انتخاب میگردد. همچنین سایر اعتبارسنجیها مانند بررسی تطابق جنسیت و زمان صحیح برای قالبها انجام میشود تا پاسخ نهایی درست و معتبر باشد.
اولین سهتایی موجود در اطلاعات واقعی، شامل اطلاعات زادگاه وودی آلن است(وودی آلن/زادگاه/نیویورک). اولین قالب از قالبهای مربوط به زادگاه، نیازمند یک اطلاعات مکانی است که این سهتایی آن را فراهم میکند. پس این قالب برای سهتایی اول انتخاب میشود. سهتایی دوم موجود در اطلاعات واقعی حاوی اطلاعات دانشگاه وودی آلن است (وودی آلن/دانشگاه/ نیویورک). اولین قالب کاندید از قالبهای مربوط به دانشگاه، نیازمند نام یک دانشگاه است که توسط این سهتایی تأمین میشود. بنابراین این قالب برای سهتایی دوم انتخاب میگردد.
موتور جستجو پس از بررسی اولیه قالبهای عبارت و انتخاب قالبهای مناسب برای هر سهتایی موجود در اطلاعات واقعی، مراحل بعدی پردازش را برای تولید پاسخ نهایی انجام میدهد. ابتدا ممکن است تطابق و سازگاری بیشتر پارامترها را بررسی کند، مثلاً بررسی کند که جنسیت موجودیت در سؤال با جنسیت فرض شده در قالبهای انتخابی مطابقت دارد یا خیر. سپس با توجه به الگوریتمهای مختلف، مانند انتخاب اولین قالب منطبق یا قالبی با بیشترین تطابق، قالبهای نهایی را از میان گزینههای کاندید انتخاب میکند. پس از آن، با جایگزین کردن فیلدهای قالبهای انتخاب شده با دادهها و اطلاعات واقعی، جمله یا جملاتی حاوی پاسخ سؤال را تولید میکند. به این ترتیب موتور پاسخدهنده میتواند پاسخی مناسب، معتبر و مبتنی بر دادههای واقعی ارائه دهد.
به عنوان مثال، موتور پاسخدهنده میتواند فیلدهای قالبهای انتخابشده را با دادههای مناسب از اطلاعات واقعی جایگزین کند و فیلدها در اولین قالب عبارت انتخابشده (یعنی “در حال حاضر در <مکان> زندگی میکند”) را با اطلاعات سهتایی اول جایگزین کند تا عبارت “در حال حاضر در شهر نیویورک زندگی میکند” تولید شود. سپس فیلدهای قالب در الگوی انتخابشده (یعنی “<موجودیت><قالب> و <قالب>/<قالب>”) را با عبارتهای تولیدشده از اولین و دومین قالبهای عبارت جایگزین میکند. بنابراین موتور پاسخدهنده جمله “وودی آلن در حال حاضر در شهر نیویورک زندگی میکند و دانشگاه محل تحصیل او دانشگاه نیویورک است” را تولید میکند. سپس پاسخی حاوی جمله تولیدشده را برای دستگاه کاربر ارسال میکند.
پاسخ تولید شده میتواند در صفحهی نتایج جستجو که حاوی جمله و سایر نتایج مرتبط است، نمایش داده شود. این صفحه همچنین شامل باکس جستجو با درخواست اصلی کاربر (مثلاً “زادگاه و دانشگاه محل تحصیل وودی آلن کجاست؟”) میباشد. سپس این صفحه توسط دستگاه کاربر نمایش داده میشود. همچنین پاسخ میتواند به صورت یک نسخه نوشتاری برای تبدیل به گفتار یا به صورت یک سیگنال صوتی رمزگذاریشده برای پخش در دستگاه کاربر ارسال شود.
نمونه ای از گراف داده
گراف داده نمونه شامل گرهها (مانند کنشگرها) و یالها (مانند روابط یا ویژگیها) است که گرهها را به هم متصل میکنند. سیستم نمایهسازی با پیمایش گراف داده، اطلاعات واقعی را به صورت سهتاییهایی مانند “وودی آلن” به عنوان موضوع (یا کنشگر)، رابطه “متولد شده است” به عنوان فعل (یا ویژگی) و “1 دسامبر 1935” به عنوان مفعول (یا مقدار)، یا “وودی آلن” به عنوان موضوع، “دارای نوع” به عنوان فعل و “شخص” به عنوان مقدار، به دست میآورد. این سهتاییها میتوانند برای انتخاب الگوهای متا توسط موتور پاسخدهنده مورد استفاده قرار گیرند.طبیعتاً گراف نمونه فقط بخشی از گراف کامل را نشان میدهد، در حالی که یک گراف کامل با تعداد زیادی کنشگر و حتی تعداد محدودی رابطه ممکن است میلیاردها سهتایی داشته باشد.
یک نمونه سهتایی دیگر که میتواند به دست آید عبارت است از کنشگر “وودی آلن” به عنوان موضوع، رابطه “ازدواج کرده با” به عنوان فعل و کنشگر “لوئیز لسر” به عنوان مقدار. برای به دست آوردن این سهتایی، سیستم نمایهسازی باید دو یال را در گراف داده پیمایش کند: از کنشگر “وودی آلن” به کنشگر “همسران وودی آلن” و سپس از کنشگر “همسران وودی آلن” به کنشگر “لوئیز لسر”. این سهتاییها میتوانند مثلاً توسط موتور پاسخدهنده برای انتخاب الگوهای متا مورد استفاده قرار گیرند.
تولید جملات در پاسخ به درخواستهای جستجو
یک سرور (مثلاً موتور پاسخدهنده) درخواست اولیهای دریافت میکند که ویژگیهای یک کنشگر را مشخص میکند. برای مثال، سرور ممکن است درخواستی دریافت کند که چندین ویژگی کنشگری (مثل سن، تاریخ تولد، محل تولد و غیره) را مشخص کند. سرور بر اساس ویژگیهای کنشگر، به مجموعهای از الگوهای کاندید برای پاسخ به درخواست دسترسی مییابد. هر الگوی کاندید شامل فیلدهایی است که هر فیلد حداقل با یک محدودیت مرتبط میشود. وقتی چندین ویژگی در درخواست اولیه مشخص شده باشد، سرور به مجموعهای از الگوهای منتخب برای هر ویژگی کنشگر دسترسی مییابد. این محدودیتها میتوانند شامل محدودیت نوع، زمانی، جنسیتی، رابطهای، مفرد/جمع، واحد اندازهگیری و تعیینکننده باشند.
سرور پس از دریافت درخواستی که ویژگیهای یک کنشگر را مشخص میکند، بر اساس این ویژگیها به مجموعهای از الگوها دسترسی پیدا میکند. سپس مجموعهای از اطلاعات مرتبط با درخواست را از منبع دادهای مبتنی بر گراف بازیابی میکند. در نهایت الگویی را انتخاب میکند که بیشترین تعداد فیلدهای قابل اعمال بر روی مجموعه اطلاعات بازیابی شده را داشته باشد. در صورتی که درخواست شامل چند ویژگی باشد، این فرآیند برای هر ویژگی تکرار میشود.
هنگامی که چندین مجموعه اطلاعات در پاسخ به یک ویژگی به دست میآید، سرور ممکن است چندین الگو را از یک مجموعه الگوهای کاندید انتخاب کند. سپس عبارتی تولید میکند، به این صورت که مجموعه اطلاعات پاسخدهنده به درخواست را به فیلدهای الگوی انتخابشده اضافه میکند تا عبارت پاسخگوی درخواست اولیه باشد. این عبارت میتواند یک جمله کامل یا بخشی از یک جمله باشد. هنگامی که چند ویژگی در درخواست اولیه وجود داشته باشد، سرور برای هر ویژگی یک عبارت تولید میکند و سپس عبارات را ترکیب میکند تا یک جمله کامل ایجاد کند.
سرور ممکن است الگوی جملهای (مثل الگوی متا) را بر اساس نوع کنشگر (مثل شخص یا مکان) به دست آورد. الگوی جمله ممکن است شامل چندین فیلد برای قرار دادن عبارات باشد. به عنوان مثال، سرور ممکن است بر اساس نوع کنشگر به مجموعهای از الگوهای متای کاندید دسترسی پیدا کند و سپس الگویی را بر اساس تعداد سهتاییهای پاسخدهنده به درخواست اولیه انتخاب کند. سپس عبارات تولیدشده را به فیلدهای الگوی جمله اضافه میکند تا جملهای تولید شود. در نهایت سرور عبارت یا جمله را به دستگاه کاربر ارسال میکند. دستگاه کاربر ممکن است عبارت را به صورت متنی نمایش دهد یا به صورت صوتی پخش کند. سرور سیگنال صوتی متناظر با عبارت یا جمله را برای دستگاه کاربر ارسال میکند.


